关于块缓冲区的管理在第八章虚拟文件系统中已有所描述,在这里我们从交换数据的角度来看一下基于缓冲区的数据交换的实现。
1.扇区及块缓冲区
块设备的每次数据传送操作都作用于一组相邻字节,我们称之为扇区。在大部分磁盘设备中,扇区的大小是512字节,但是现在新出现的一些设备使用更大的扇区(1024和2014字节)。注意,应该把扇区作为数据传送的基本单元:不允许传送少于一个扇区的数据,而大部分磁盘设备都可以同时传送几个相邻的扇区。
所谓块就是块设备驱动程序在一次单独操作中所传送的一大块相邻字节。注意不要混淆块(block)和扇区(sector):扇区是硬件设备传送数据的基本单元,而块只是硬件设备请求一次I/O操作所涉及的一组相邻字节。
在Linux中,块大小必须是2的幂,而且不能超过一个页面。此外,它必须是扇区大小的整数倍,因为每个块必须包含整数个扇区。因此,在PC体系结构中,允许块的大小为512、1024、2048和4096字节。同一个块设备驱动程序可以作用于多个块大小,因为它必须处理共享同一主设备号的一组设备文件,而每个块设备文件都有自己预定义的块大小。例如,一个块设备驱动程序可能会处理有两个分区的硬盘,一个分区包含Ext2文件系统,另一个分区包含交换分区。
内核在一个名为blksize_size的表中存放块的大小;表中每个元素的索引就是相应块设备文件的主设备号和次设备号。如果blksize_size[M]为NULL,那么共享主设备号M的所有块设备都使用标准的块大小,即1024字节。
每个块都需要自己的缓冲区,它是内核用来存放块内容的RAM内存区。当设备驱动程序从磁盘读出一个块时,就用从硬件设备中所获得的值来填充相应的缓冲区;同样,当设备驱动程序向磁盘中写入一个块时,就用相关缓冲区的实际值来更新硬件设备上相应的一组相邻字节。缓冲区的大小一定要与块的大小相匹配。
2.块驱动程序的体系结构
下面我们说明通用块驱动程序的体系结构,以及在为缓冲区I/O操作时所涉及的主要成分。
块设备驱动程序通常分为两部分,即高级驱动程序和低级驱动程序,前者处理VFS层,后者处理硬件设备,如图11.7所示:
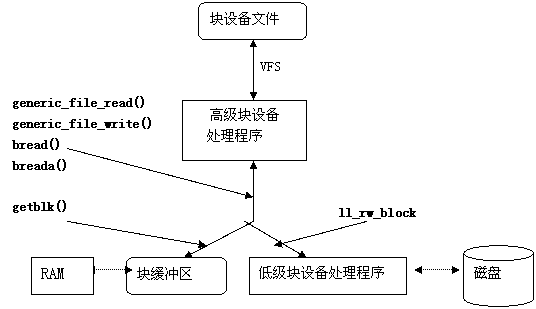
图11.7 块设备驱动程序的体系结构
假设进程对一个设备文件发出read( )或write( )系统调用。VFS执行对应文件对象的read或write方法,由此就调用高级块设备处理程序中的一个过程。这个过程执行的所有操作都与对这个硬件设备的具体读写请求有关。内核提供两个名为generic_file_read ( )和generic_file_write ( )通用函数来留意所有事件的发生。因此,在大部分情况下,高级硬件设备驱动程序不必做什么,而设备文件的read和write方法分别指向generic_file_read
( )和generic_file_write ( )方法。
但是,有些块设备的处理程序需要自己专用的高级设备驱动程序。典型的例子是软驱的设备驱动程序:它必须检查从上次访问磁盘以来,用户有没有改变驱动器中的磁盘;如果已插入一张新磁盘,那么设备驱动程序必须使缓冲区中所包含的旧数据无效。
即使高级设备驱动程序有自己的read和write方法,但是这两个方法通常最终还会调用generic_file_read ( )和generic_file_write ( )函数。这些函数把对I/O设备文件的访问请求转换成对相应硬件设备的块请求。所请求的块可能已在主存,因此generic_file_read ( )和generic_file_write ( )函数调用getblk( )函数来检查缓冲区中是否已经预取了块,还是从上次访问以来缓冲区一直都没有改变。如果块不在缓冲区中,getblk( )就必须调用ll_rw_block( )继续从磁盘中读取这个块,后面这个函数激活操纵设备控制器的低级驱动程序,以执行对块设备所请求的操作。
在VFS直接访问某一块设备上的特定块时,也会触发缓冲区I/O操作。例如,如果内核必须从磁盘文件系统中读取一个索引节点,那么它必须从相应磁盘分区的块中传送数据 。对于特定块的直接访问是由bread( )和breada( )函数来执行的,这两个函数又会调用前面提到过的getblk( )和ll_rw_block( )函数。
由于块设备速度很慢,因此缓冲区I/O数据传送通常都是异步处理的:低级设备驱动程序对DMAC和磁盘控制器进行编程来控制其操作,然后结束。当数据传送完成时,就会产生一个中断,从而第二次激活这个低级设备驱动程序来清除这次I/O操作所涉及的数据结构。
3.块设备请求
虽然块设备驱动程序可以一次传送一个单独的数据块,但是内核并不会为磁盘上每个被访问的数据块都单独执行一次I/O操作:这会导致磁盘性能的下降,因为确定磁盘表面块的物理位置是相当费时的。取而代之的是,只要可能,内核就试图把几个块合并在一起,并作为一个整体来处理,这样就减少了磁头的平均移动时间。
当进程、VFS层或者任何其他的内核部分要读写一个磁盘块时,就真正引起一个块设备请求。从本质上说,这个请求描述的是所请求的块以及要对它执行的操作类型(读还是写)。然而,并不是请求一发出,内核就满足它,实际上,块请求发出时I/O操作仅仅被调度,稍后才会被执行。这种人为的延迟有悖于提高块设备性能的关键机制。当请求传送一个新的数据块时,内核检查能否通过稍微扩大前一个一直处于等待状态的请求而满足这个新请求,也就是说,能否不用进一步的搜索操作就能满足新请求。由于磁盘的访问大都是顺序的,因此这种简单机制就非常高效。
延迟请求复杂化了块设备的处理。例如,假设某个进程打开了一个普通文件,然后,文件系统的驱动程序就要从磁盘读取相应的索引节点。高级块设备驱动程序把这个请求加入一个等待队列,并把这个进程挂起,直到存放索引节点的块被传送为止。
因为块设备驱动程序是中断驱动的,因此,只要高级驱动程序一发出块请求,它就可以终止执行。在稍后的时间低级驱动程序才被激活,它会调用一个所谓的策略程序从一个队列中取得这个请求,并向磁盘控制器发出适当的命令来满足这个请求。当I/O操作完成时,磁盘控制器就产生一个中断,如果需要,相应的处理程序会再次调用这个策略程序来处理队列中进程的下一个请求。
每个块设备驱动程序都维护自己的请求队列;每个物理块设备都应该有一个请求队列,以提高磁盘性能的方式对请求进行排序。因此策略程序就可以顺序扫描这种队列,并以最少地移动磁头而为所有的请求提供服务。
每个块设备请求都是由一个request结构来描述的,其定义于include/linux/blkdev.h:
/*
* Ok, this is an expanded form so that
we can use the same
* request for
paging requests.
*/
struct
request {
struct list_head queue;
int elevator_sequence;
volatile int rq_status; /* should split this
into a few status bits */
#define RQ_INACTIVE
(-1)
#define
RQ_ACTIVE
1
#define
RQ_SCSI_BUSY
0xffff
#define
RQ_SCSI_DONE
0xfffe
#define
RQ_SCSI_DISCONNECTING 0xffe0
kdev_t rq_dev;
int cmd;
/* READ or WRITE */
int errors;
unsigned long sector;
unsigned long nr_sectors;
unsigned long hard_sector, hard_nr_sectors;
unsigned int nr_segments;
unsigned int nr_hw_segments;
unsigned long current_nr_sectors;
void * special;
char * buffer;
struct completion * waiting;
struct buffer_head * bh;
struct buffer_head * bhtail;
request_queue_t *q;
};
从代码注释可以知道,在2.2以前的版本中没有这么多域,很多域时为分页请求而增加的,我们暂且不予考虑。在此,我们只说明与块传送有关的域。为了描述方便起见,我们把struct request叫做请求描述符。
数据传送的方向存放在cmd域中:该值可能是READ(把数据从块设备读到RAM中)或者WRITE(把数据从RAM写到块设备中)。rq_status域用来定义请求的状态:对于大部分块设备来说,这个域的值可能为RQ_INACTIVE(请求描述符还没有使用)或者RQ_ACTIVE(有效的请求,低级设备驱动程序要对其服务或正在对其服务)。
一次请求可能包括同一设备中的很多相邻块。rq_dev域指定块设备,而sector域说明请求中第一个块对应的第一个扇区的编号。nr_sector和current_nr_sector给出要传送数据的扇区数。sector、nr_sector和current_nr_sector域都可以在请求得到服务的过程中而被动态修改。
请求块的所有缓冲区首部都被集中在一个简单链表中。每个缓冲区首部的b_reqnext域指向链表中的下一个元素,而请求描述符的bh和bhtail域分别指向链表的第一个元素和最后一个元素。
请求描述符的buffer域指向实际数据传送所使用的内存区。如果只请求一个单独的块,那么缓冲区只是缓冲区首部的b_data域的一个拷贝。然而,如果请求了多个块,而这些块的缓冲区在内存中又不是连续的,那么就使用缓冲区首部的b_reqnext域把这些缓冲区链接在一起。对于读操作来说,低级设备驱动程序可以选择先分配一个大的内存区来立即读取请求的所有扇区,然后再把这些数据拷贝到各个缓冲区。同样,对于写操作来说,低级设备驱动程序可以把很多不连续缓冲区中的数据拷贝到一个单独内存区的缓冲区中,然后再立即执行整个数据的传送。
另外,在严重负载和磁盘操作频繁的情况下,固定数目的请求描述符就可能成为一个瓶颈。空闲描述符的缺乏可能会强制进程等待直到正在执行的数据传送结束。因此,request_queue_t 类型(见下面)中的wait_for_request等待队列就用来对正在等待空闲请求描述符的进程进行排队。get_request_wait( )试图获取一个空闲的请求描述符,如果没有找到,就让当前进程在等待队列中睡眠;get_request( )函数与之类似,但是如果没有可用的空闲请求描述符,它只是简单地返回NULL。
4. 请求队列
请求队列只是一个简单的链表,其元素是请求描述符。每个请求描述符中的next域都指向请求队列的下一个元素,最后一个元素为空。这个链表的排序通常是:首先根据设备标识符,其次根据最初的扇区号。
如前所述,对于所服务的每个硬盘,设备驱动程序通常都有一个请求队列。然而,一些设备驱动程序只有一个请求队列,其中包括了由这个驱动器处理的所有物理设备的请求。这种方法简化了驱动程序的设计,但是损失了系统的整体性能,因为不能对队列强制使用简单排序的策略。请求队列定义如下:
struct
request_queue
{
/*
* the queue request freelist, one for reads and
one for writes
*/
struct request_list rq[2];
/*
* Together with queue_head for cacheline sharing
*/
struct list_head
queue_head;
elevator_t
elevator;
request_fn_proc
* request_fn;
merge_request_fn *
back_merge_fn;
merge_request_fn *
front_merge_fn;
merge_requests_fn *
merge_requests_fn;
make_request_fn
* make_request_fn;
plug_device_fn
* plug_device_fn;
/*
* The queue owner gets to use this for whatever they like.
* ll_rw_blk doesn't touch it.
*/
void
* queuedata;
/*
* This is used to remove the plug when tq_disk runs.
*/
struct tq_struct
plug_tq;
/*
* Boolean that indicates whether this queue is plugged or not.
*/
char
plugged;
/*
* Boolean that indicates whether current_request is active or
* not.
*/
char
head_active;
/*
* Is meant to protect the queue in the future instead of
* io_request_lock
*/
spinlock_t
queue_lock;
/*
* Tasks wait here for free request
*/
wait_queue_head_t
wait_for_request;
};
typedef
struct request_queue request_queue_t;
其中,request_list为请求描述符组成的空闲链表,其定义如下:
struct
request_list {
unsigned int count;
struct list_head free;
};
有两个这样的链表,一个用于读,一个用于写。
elevator_t 结构描述的是为磁盘的电梯调度算法而设的数据结构。从request_fn_proc到plug_device_fn 都是一些函数指针。例如request_fn是一个指针,指向类型为
request_fn_proc 的对象。而request_fn_proc则通过#typedef定义为一种函数:
typedef
void (request_fn_proc) (request_queue_t *q)
其余的函数也与此类似,这些指针(连同其他域)都是在相应设备初始化时设置好的。需要对一个块设备进行操作时,就为之设置好一个数据结构request_queue。并将其挂入相应的请求队列中。
这里要说明的是,request_fn(
)域包含驱动程序的策略程序的地址,策略程序是低级块设备驱动程序的关键函数,为了开始传送队列中的一个请求所指定的数据,它与物理块设备(通常是磁盘控制器)真正打交道。
5. 块设备驱动程序描述符
驱动程序描述符是一个blk_dev_struct类型的数据结构,其定义如下:
struct blk_dev_struct {
/*
* queue_proc has to be atomic
*/
request_queue_t
request_queue;
queue_proc
*queue;
void
*data;
};
在这个结构中,其主体是请求队列request_queue;此外,还有一个函数指针queue,当这个指针为非0时,就调用这个函数来找到具体设备的请求队列,这是为考虑具有同一主设备号的多种同类设备而设的一个域。这个指针也在设备初始化是就设置好,另一个指针data是辅助queue函数找到特定设备的请求队列。
所有块设备的描述符都存放在blk_dev表中:
struct
blk_dev_struct blk_dev[MAX_BLKDEV];
每个块设备都对应着数组中的一项,可以用主设备号进行检索。每当用户进程对一个块
设备发出一个读写请求时,首先调用块设备所公用的函数 generic_file_read
( )和generic_file_write ( ),如果数据存在缓冲区中或缓冲区还可以存放数据,就同缓冲区进行数据交换。否则,系统会将相应的请求队列结构添加到其对应项的 blk_dev_struct 中,如图11.8所示。如果在加入请求队列结构的时候该设备没有请求的话,则马上响应该请求,否则将其追加到请求任务队列尾顺序执行。
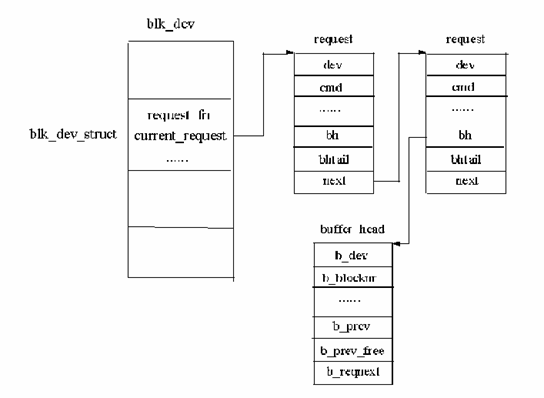
图11.8
块设备读写请求
图11.8表示每个请求有指向一个或多个 buffer_hear 结构的指针,每个请求读写一块数据。如果系统对 buffer_head 结构上锁, 则进程会等待到对此缓冲区的块操作完成。一旦设备驱动程序完成了请求则它必须将每个 buffer_heard 结构从 request 结构中清除,将它们标记成已更新状态并对它们解锁。对 buffer_head 的解锁将唤醒所有等待此块操作完成的睡眠进程,然后request
数据结构被标记成空闲以便被其它块请求使用。