在传输过程中,存在着多个套接字缓冲区,这些缓冲区组成一个链表,每个链表都有一个链表头sk_buff_head
,链表中每个节点分别对应内存中一块的数据区。因此对它的操作有两种基本方式:第一种是对缓冲区链表进行操作;第二种是对缓冲区对应的数据区进行控制。
当我们向物理接口发送数据时或当我们从物理接口接收数据时,我们就利用链表操作;当我们要对数据区的内容进行处理时,我们就利用内存操作例程。这种操作机制对网络传输是非常有效的。
前面我们讲过,每个协议都要在发送数据时向缓冲区添加自己的协议头和协议尾,而在接收数据时去掉协议头和协议尾,那么具体的操作是怎样进行的呢?我们先看看对缓冲区操作的两个基本的函数:
void
append_frame(char *buf, int len){
struct sk_buff *skb=alloc_skb(len, GFP_ATOMIC); /*创建一个缓冲区*/
if(skb==NULL)
my_dropped++;
else
{
kb_put(skb,len);
memcpy(skb->data,data,len); /*向缓冲区添加数据*/
skb_append(&my_list, skb);
/*将该缓冲区加入缓冲区队列*/
}
}
void
process_frame(void){
struct sk_buff *skb;
while((skb=skb_dequeue(&my_list))!=NULL)
{
process_data(skb);
/*将缓冲区的数据传递给协议层*/
kfree_skb(skb, FREE_READ);
/*释放缓冲区,缓冲区从此消失*/
}
}
这两个非常简单的程序片段,虽然它们不是源程序,但是它们恰当地描述了处理数据包的工作原理,append_frame( )描述了分配缓冲区。创建数据包过程process_frame( )描述了传递数据包,释放缓冲区的的过程。关于它们的源程序,可以去参见 net/core/dev.c 中netif_rx( )函数和 net_bh( )函数。你可以看出它们和上面我们提到的两个函数非常相似。这两个函数非常复杂,因为他们必须保证数据能够被正确的协议接收并且要负责流程的控制,但是他们最基本的操作是相同的。
让我们再看看上面提到的函数--append_frame( )。当 alloc_skb( ) 函数获得一个长度为
len字节的缓冲区(如图12.12 (a))后,该缓冲区包含以下内容:
◆缓冲区的头部有零字节的头部空间
◆零字节的数据空间
◆缓冲区的尾部有零字节的尾部空间
再看skb_put( )函数(如图12.12 (d)),它的作用是从数据区的尾部向缓冲区尾部不断扩大数据区大小,为后面的memcpy( )函数分配空间。
当一个缓冲区创建以后,所有的可用空间都在缓冲区的尾部。在没有向其中添加数据之前,首先被执行的函数调用是 skb_receive( )(如图12.12 (b)),它使你在缓冲区头部指定一定的空闲空间,因此许多发送数据的例程都是这样开头的:
skb=alloc_skb(len+headspace, GFP_KERNEL);
skb_reserve(skb, headspace);
skb_put(skb,len);
memcpy_fromfs(skb->data,data,len);
pass_to_m_protocol(skb);
图12.12向我们展示了以上过程进行时,sk_buff 的变化情况:
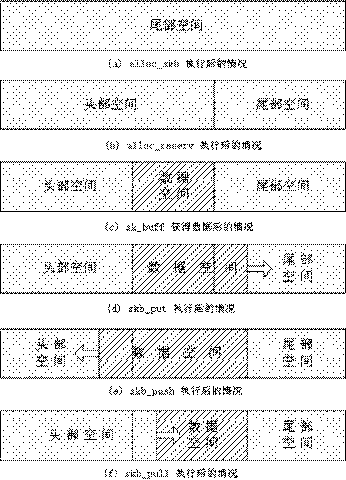
图12.12 sk_buff 的变化过程