从原理上说,kswapd相当于一个进程,它有自己的进程控制块task_struct结构。与其它进程一样受内核的调度。而正因为内核将它按进程来调度,就可以让它在系统相对空闲的时候来运行。不过,与普通进程相比,kswapd有其特殊性。首先,它没有自己独立的地址空间,所以在近代操作系统理论中把它称为“线程”以与进程相区别。那么,kswapd的地址空间是什么?实际上,内核空间就是它的地址空间。在这一点上,它与中断服务例程相似。其次,它的代码是静态地链接在内核中的,因此,可以直接调用内核中的各种子程序和函数。
Kswapd的源代码基本上都在mm/vmscan.c中,图6.18给出了kswapd中与交换有关的主要函数调用关系。
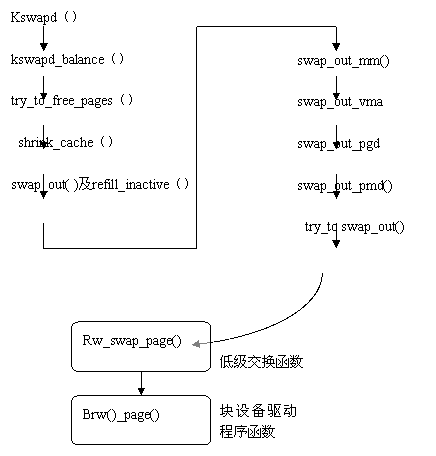
图
6.18 kswapd 的实现代码中与交换相关的主要函数的调用关系
从上面的调用关系可以看出, kswapd的实现相当复杂,这不仅仅涉及复杂的页面交换技术,还涉及与磁盘相关的具体文件操作,因此,为了理清思路,搞清主要内容,我们对一些主要函数给予描述:
1.Kswapd()
在Linux
int kswapd(void *unused)
{
struct task_struct *tsk = current;
DECLARE_WAITQUEUE(wait, tsk);
daemonize(); /*内核线程的初始化*/
strcpy(tsk->comm, "kswapd");
sigfillset(&tsk->blocked);
/*把进程PCB中的阻塞标志位全部置为1*/
/*
* Tell the memory management that we're a "memory allocator",
* and that if we need more memory we should get
access to it
* regardless (see "__alloc_pages()").
"kswapd" should
* never get caught in the normal page freeing
logic.
*
* (Kswapd normally doesn't need memory anyway, but sometimes
* you need a small amount of memory in order to
be able to
* page out something else, and this flag
essentially protects
* us from recursively trying to free more
memory as we're
* trying to free the first piece of memory in the first place).
*/
tsk->flags |= PF_MEMALLOC; /*这个标志表示给kswapd要留一定的内存*/
/*
* Kswapd main loop.
*/
for (;;) {
__set_current_state(TASK_INTERRUPTIBLE);
add_wait_queue(&kswapd_wait, &wait); /*把kswapd
加入等待队列*/
mb(); /*增加一条汇编指令*/
if (kswapd_can_sleep())
/*检查调度标志是否置位*/
schedule();
/*调用调度程序*/
_set_current_state(TASK_RUNNING); /*让kswapd
处于就绪状态*/
remove_wait_queue(&kswapd_wait, &wait); /*把kswapd
从等待队列删除*/
/*
* If we actually get into a low-memory situation,
* the processes needing more memory will wake
us
* up on a more timely basis.
*/
kswapd_balance(); /*
kswapd 的核心函数,请看后面内容*/
run_task_queue(&tq_disk);
/*运行tq_disk 队列中的例程*/
}
}
kswapd内核线程的创建如下:
static int __init kswapd_init(void)
{
printk("Starting kswapd\n");
swap_setup();
kernel_thread(kswapd, NULL, CLONE_FS |
CLONE_FILES | CLONE_SIGNAL);
return 0;
}
函数kswapd_init()是在系统初始化期间被调用的。它主要做两件事,其中swap_setup()根据物理内存的大小设定一个全局变量page_cluster。这是一个与磁盘设备驱动有关的参数。由于读磁盘时先要经过寻道,而寻道是比较费时的操作,因此,为了节省时间,每次最好多读几个页面,这叫“预读”。到底每次预读几个页面,就是由这个函数根据内存本身的大小给出的(为2,3或4)。另外一个主要的任务就是调用kernel_thread()创建内核线程kswapd。
从上面的介绍可以看出,kswapd成为内核的一个线程,其主循环是一个无限循环。循环一开始,把它加入等待队列,但如果调度标志为1,就执行调度程序,紧接着就又把它从等待队列删除,将其状态变为就绪。只要调度程序再次执行,它就会得到执行,如此周而复始进行下去。
2.kswapd_balance()函数
从该函数的名字可以看出,这是一个要求得平衡的函数,那么,求得什么样的平衡呢?在本章的初始化一节中,我们介绍了物理内存的三个层次,即存储节点、管理区和页面。所谓平衡就是对页面的释放要均衡地在各个存储节点、管理区中进行,代码如下:
static void kswapd_balance(void)
{
int need_more_balance;
pg_data_t * pgdat;
do {
need_more_balance = 0;
pgdat = pgdat_list;
do
need_more_balance |= kswapd_balance_pgdat(pgdat);
while ((pgdat = pgdat->node_next));
}
while (need_more_balance);
}
这个函数比较简单,主要是对每个存储节点进行扫描。然后又调用kswapd_balance_pgdat()对每个管理区进行扫描:
static int kswapd_balance_pgdat(pg_data_t * pgdat)
{
int need_more_balance = 0, i;
zone_t * zone;
for (i = pgdat->nr_zones-1; i >= 0; i--)
{
zone = pgdat->node_zones + i;
if (unlikely(current->need_resched))
schedule();
if (!zone->need_balance)
continue;
if (!try_to_free_pages(zone, GFP_KSWAPD, 0)) {
zone->need_balance = 0;
__set_current_state(TASK_INTERRUPTIBLE);
schedule_timeout(HZ);
continue;
}
if (check_classzone_need_balance(zone))
need_more_balance = 1;
else
zone->need_balance = 0;
}
其中,最主要的函数是try_to_free_pages(),能否调用这个函数取决于平衡标志need_balance是否为1,也就是说看某个管理区的空闲页面数是否小于最高警戒线,这是由check_classzone_need_balance()函数决定的。当某个管理区的空闲页面数小于其最高警戒线时就调用try_to_free_pages()。
3.try_to_free_pages()
该函数代码如下:
int try_to_free_pages(zone_t *classzone, unsigned int
gfp_mask, unsigned int order)
{
int priority = DEF_PRIORITY;
int nr_pages = SWAP_CLUSTER_MAX;
gfp_mask = pf_gfp_mask(gfp_mask);
do {
nr_pages = shrink_caches(classzone, priority,
gfp_mask, nr_pages);
if (nr_pages <= 0)
return 1;
}
while (--priority);
/*
* Hmm.. Cache shrink failed - time to kill something?
* Mhwahahhaha! This is the part I really like. Giggle.
*/
out_of_memory();
return 0;
}
其中的优先级表示对队列进行扫描的长度,缺省的优先级DEF_PRIORITY为6(最低优先级)。假定队列长度为L,优先级6就表示要扫描的队列长度为L/26,所以这个循环至少循环6次。nr_pages为要换出的页面数,其最大值SWAP_CLUSTER_MAX为32。其中主要调用的函数为shrink_caches():
static int shrink_caches(zone_t * classzone, int priority,
unsigned int gfp_mask, int nr_pages)
{
int chunk_size = nr_pages;
unsigned long ratio;
nr_pages -= kmem_cache_reap(gfp_mask);
if (nr_pages <= 0)
return 0;
nr_pages = chunk_size;
/* try to keep the active list 2/3 of the size of the cache */
ratio = (unsigned long) nr_pages *
nr_active_pages / ((nr_inactive_pages + 1) * 2);
refill_inactive(ratio);
nr_pages = shrink_cache(nr_pages, classzone,
gfp_mask, priority);
if (nr_pages <= 0)
return 0;
shrink_dcache_memory(priority, gfp_mask);
shrink_icache_memory(priority, gfp_mask);
1 #ifdef CONFIG_QUOTA
shrink_dqcache_memory(DEF_PRIORITY, gfp_mask);
#endif
return nr_pages;
}
其中kmem_cache_reap()函数“收割(reap)”由Slab机制管理的空闲页面。如果从Slap回收的页面数已经达到要换出的页面数nr_pages,就不用从其它地方进行换出。refill_inactive()函数把活跃队列中的页面移到非活跃队列。shrink_cache()函数把一个“洗净”且未加锁的页面移到非活跃队列,以便该页能被尽快释放。
此外,除了从各个进程的用户空间所映射的物理页面中回收页面外,还调用shrink_dcache_memory()、shrink_icache_memory()及shrink_dqcache_memory()回收内核数据结构所占用的空间。在文件系统一章将会看到,在打开文件的过程中,要分配和使用代表着目录项的dentry数据结构,还有代表着文件索引节点inode的数据结构。这些数据结构在文件关闭后并不立即释放,而是放在LRU队列中作为后备,以防在不久将来的文件操作中又用到。这样经过一段时间后,就有可能积累起大量的dentry数据结构和inode数据结构,从而占用数量可观的物理页面。这时,就要通过这些函数适当加以回收。
4.页面置换
到底哪些页面会被作为后选页以备换出,这是由Swap_out()和shrink_cache()一起完成的。这个过程比较复杂,这里我们抛开源代码,以理清思路为目标。
shrink_cache()要做很多换出的准备工作。它关注两个队列:“活跃的” LRU 队列 和 “非活跃的” FIFO 队列,每个队列都是struct page形成的链表。该函数的代码比较长,我们把它所做的工作概述如下:
·
把引用过的页面从活跃队列的队尾移到该队列的队头(实现LRU策略)。
·
把未引用过的页面从活跃队列的队尾移到非活跃队列的队头(为准备换出而排队)。
·
把脏页面安排在非活跃队列的队尾准备写到磁盘。
·
从非活跃队列的队尾恢复干净页面(写出的页面就成为干净的)