页表的实现对虚拟内存系统效率是极为关键的。例如把一个寄存器的内容复制到另一个寄存器中的一条指令,在不使用分页时,只需访问内存一次取指令,而在使用分页时需要额外的内存访问去读取页表。而系统的运行速度一般是被cpu从内存中取得指令和数据的速率限制的,如果在每次访问内存时都要访问两次内存会使系统性能降低三分之二。
对这个问题的解决,有人提出了一个解决方案,这个方案基于这样的观察:大部分程序倾向于对较少的页面进行大量的访问。因此,只有一小部分页表项经常被用到,其它的很少被使用。
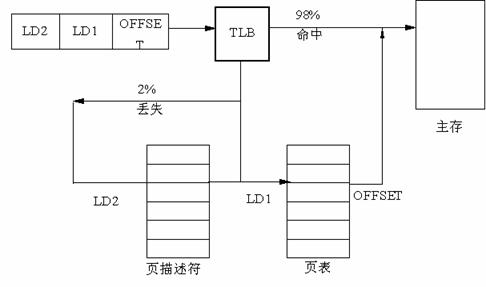
图6.20 翻译后援存储器
采取的解决办法是为计算机装备一个不需要经过页表就能把虚拟地址映射成物理地址的小的硬件设备,这个设备叫做TLB(翻译后援存储器,Translation Lookside Buffer), 有时也叫做相联存储器(associative memory),如图6.20所示 。它通常在MMU内部,条目的数量较少,在这个例子中是6个,80386有32个。
每一个TLB寄存器的每个条目包含一个页面的信息:有效位,虚页面号,修改位,保护码,和页面所在的物理页面号,它们和页面表中的表项一一对应,如图6.21所示。
|
段号 |
虚页面号 |
页面框 |
保护 |
年龄 |
有效位 |
|
4 |
1 |
7 |
RW |
5 |
1 |
|
8 |
7 |
16 |
RW |
1 |
1 |
|
2 |
0 |
33 |
RX |
4 |
1 |
|
4 |
4 |
72 |
RX |
13 |
0 |
|
5 |
8 |
17 |
RW |
2 |
1 |
|
2 |
7 |
34 |
RX |
2 |
1 |
图6.21用于加速分页面操作的TLB
当一个虚地址被送到MMU翻译时,硬件首先把它和TLB中的所有条目同时(并行地)进行比较,如果它的虚页号在TLB中,并且访问没有违反保护位,它的页面会直接从TLB中取出而不去访问页表,如虚页面号在TLB但当前指令试图写一个只读的页面,这时将产生一个缺页异常,与直接访问页表时相同。
如MMU发现在TLB中没有命中,它将随即进行一次常规的页表查找,然后从TLB中淘汰一个条目并把它替换为刚刚找到的页表项。因此如果这个页面很快再被用到的话,第二次访问时它就能在TLB中直接找到。在一个TLB 条目被淘汰时,被修改的位被复制回在内存中的页表项,其它的值则已经在那里了。当TLB从页表装入时,所有的域都从内存中取得。
必须明确在分页机制中,TLB中的数据和页表中的数据的相关性,不是由处理器进行维护,而是必须由操作系统来维护,高速缓存的刷新是通过装入处理器(80386)中的寄存器CR3来完成的。(见刷新机制flush_tlb())
这里要还提到命中率,即一个页面在TBL中找到的概率。一般来说TLB的尺寸大可增加命中率,但会增加成本和软件的管理。所以一般都采用8--64个条目的数量。
假如命中率是0.85,访问内存时间是120那秒,访TLB时间是15那秒。那么访问时间是:0.85*(15+120)+(1-0.85)*(15+120+120)=153那秒。