新的进程通过克隆旧的程序(当前进程)而建立。fork() 和 clone()(对于线程)系统调用可用来建立新的进程。这两个系统调用结束时,内核在系统的物理内存中为新的进程分配新的 task_struct 结构,同时为新进程要使用的堆栈分配物理页。Linux 还会为新的进程分配新的进程标识符。然后,新 task_struct 结构的地址保存在链表中,而旧进程的 task_struct 结构内容被复制到新进程的 task_struct 结构中。
在克隆进程时,Linux 允许两个进程共享相同的资源。可共享的资源包括文件、信号处理程序和虚拟内存等(通过继承)。当某个资源被共享时,该资源的引用计数值会增加 1,从而只有两个进程均终止时,内核才会释放这些资源。图 6.23 说明了父进程和子进程共享打开的文件。
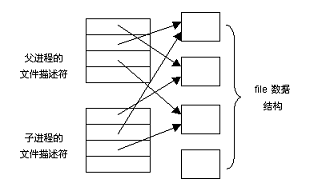
图 6.23父进程和子进程共享打开的文件
系统对进程虚拟内存的克隆过程则更加巧妙些。新的 vm_area_struct 结构、新进程自己的 mm_struct 结构以及新进程的页表必须在一开始就准备好,但这时并不复制任何虚拟内存。如果旧进程的某些虚拟内存在物理内存中,而有些在交换文件中,那么虚拟内存的复制将会非常困难和费时。实际上,Linux 采用了称为写时复制的技术,也就是说,只有当两个进程中的任意一个向虚拟内存中写入数据时才复制相应的虚拟内存;而没有写入的任何内存页均可以在两个进程之间共享。代码页实际总是可以共享的。
此外,内核线程是调用kernel_thread()函数创建的,而kernel_thread()在内核态调用了clone()系统调用。内核线程通常没有用户地址空间,即p->mm = NULL,它总是直接访问内核地址空间。
不管是fork()还是clone()系统调用,最终都调用了内核中的do_fork(),其源代码在kernel/fork.c:
/*
* Ok, this is
the main fork-routine. It copies the system process
* information (task[nr]) and sets up the necessary registers.
It also
* copies the data segment in its entirety. The "stack_start" and
*
"stack_top" arguments are simply passed along to the platform
* specific copy_thread() routine. Most platforms ignore stack_top.
* For an example
that's using stack_top, see
* arch/ia64/kernel/process.c.
*/
int do_fork(unsigned long clone_flags, unsigned long
stack_start,
struct pt_regs *regs, unsigned long stack_size)
{
int retval;
struct task_struct *p;
struct completion vfork;
retval = -EPERM;
/*
* CLONE_PID is only allowed for the initial SMP swapper
* calls
*/
if (clone_flags & CLONE_PID) {
if (current->pid)
goto fork_out;
}
retval = -ENOMEM;
p =
alloc_task_struct();
if (!p)
goto fork_out;
*p =
*current;
retval = -EAGAIN;
/*
* Check if we are over our maximum process limit, but be sure to
* exclude root. This is needed to make it possible for login and
* friends to set the per-user process limit to
something lower
* than the amount of processes root is running.
-- Rik
*/
if
(atomic_read(&p->user->processes) >=
p->rlim[RLIMIT_NPROC].rlim_cur
&& !capable(CAP_SYS_ADMIN)
!capable(CAP_SYS_RESOURCE))
goto bad_fork_free;
atomic_inc(&p->user->__count);
atomic_inc(&p->user->processes);
/*
* Counter increases are protected by
* the kernel lock so nr_threads can't
* increase under us (but it may decrease).
*/
if (nr_threads >= max_threads)
goto bad_fork_cleanup_count;
get_exec_domain(p->exec_domain);
if (p->binfmt &&
p->binfmt->module)
__MOD_INC_USE_COUNT(p->binfmt->module);
p->did_exec = 0;
p->swappable = 0;
p->state = TASK_UNINTERRUPTIBLE;
copy_flags(clone_flags, p);
p->pid = get_pid(clone_flags);
p->run_list.next = NULL;
p->run_list.prev = NULL;
p->p_cptr = NULL;
init_waitqueue_head(&p->wait_chldexit);
p->vfork_done = NULL;
if (clone_flags & CLONE_VFORK) {
p->vfork_done = &vfork;
init_completion(&vfork);
}
spin_lock_init(&p->alloc_lock);
p->sigpending = 0;
init_sigpending(&p->pending);
p->it_real_value = p->it_virt_value =
p->it_prof_value = 0;
p->it_real_incr = p->it_virt_incr =
p->it_prof_incr = 0;
init_timer(&p->real_timer);
p->real_timer.data = (unsigned long) p;
p->leader = 0;
/* session leadership doesn't inherit */
p->tty_old_pgrp = 0;
p->times.tms_utime = p->times.tms_stime =
0;
p->times.tms_cutime = p->times.tms_cstime
= 0;
#ifdef CONFIG_SMP
{
int i;
p->cpus_runnable = ~0UL;
p->processor = current->processor;
/* ?? should we just memset this ?? */
for(i = 0; i < smp_num_cpus; i++)
p->per_cpu_utime[i] = p->per_cpu_stime[i]
= 0;
spin_lock_init(&p->sigmask_lock);
}
#endif
p->lock_depth = -1;
/* -1 = no lock */
p->start_time = jiffies;
INIT_LIST_HEAD(&p->local_pages);
retval = -ENOMEM;
/* copy all the process information */
if (copy_files(clone_flags, p))
goto bad_fork_cleanup;
if (copy_fs(clone_flags, p))
goto bad_fork_cleanup_files;
if (copy_sighand(clone_flags, p))
goto bad_fork_cleanup_fs;
if (copy_mm(clone_flags, p))
goto bad_fork_cleanup_sighand;
retval = copy_thread(0, clone_flags, stack_start,
stack_size, p, regs);
if (retval)
goto bad_fork_cleanup_mm;
p->semundo = NULL;
/* Our parent execution domain becomes current domain
These must match for thread signalling to apply */
p->parent_exec_id = p->self_exec_id;
/* ok, now we should be set up.. */
p->swappable = 1;
p->exit_signal = clone_flags & CSIGNAL;
p->pdeath_signal = 0;
/*
* "share" dynamic priority between parent and child, thus the
* total amount of dynamic priorities in the
system doesnt change,
* more scheduling fairness. This is only
important in the first
* timeslice, on the long run the scheduling
behaviour is unchanged.
*/
p->counter = (current->counter + 1) >> 1;
current->counter >>= 1;
if (!current->counter)
current->need_resched = 1;
/*
* Ok, add it to the run-queues and make it
* visible to the rest of the system.
*
* Let it rip!
*/
retval = p->pid;
p->tgid = retval;
INIT_LIST_HEAD(&p->thread_group);
/*
Need tasklist lock for parent etc handling! */
write_lock_irq(&tasklist_lock);
/*
CLONE_PARENT and CLONE_THREAD re-use the old parent */
p->p_opptr = current->p_opptr;
p->p_pptr = current->p_pptr;
if (!(clone_flags & (CLONE_PARENT |
CLONE_THREAD))) {
p->p_opptr = current;
if (!(p->ptrace & PT_PTRACED))
p->p_pptr = current;
}
if (clone_flags & CLONE_THREAD) {
p->tgid = current->tgid;
list_add(&p->thread_group,
¤t->thread_group);
}
SET_LINKS(p);
hash_pid(p);
nr_threads++;
write_unlock_irq(&tasklist_lock);
if (p->ptrace & PT_PTRACED)
send_sig(SIGSTOP, p, 1);
wake_up_process(p);
/* do this last */
++total_forks;
if (clone_flags & CLONE_VFORK)
wait_for_completion(&vfork);
fork_out:
return retval;
bad_fork_cleanup_mm:
exit_mm(p);
bad_fork_cleanup_sighand:
exit_sighand(p);
bad_fork_cleanup_fs:
exit_fs(p); /* blocking */
bad_fork_cleanup_files:
exit_files(p); /* blocking */
bad_fork_cleanup:
put_exec_domain(p->exec_domain);
if (p->binfmt && p->binfmt->module)
__MOD_DEC_USE_COUNT(p->binfmt->module);
bad_fork_cleanup_count:
atomic_dec(&p->user->processes);
free_uid(p->user);
bad_fork_free:
free_task_struct(p);
goto fork_out;
}
尽管fork()系统调用因为传递用户堆栈和寄存器参数而与特定的平台相关,但实际上do_fork()所做的工作还是可移植的。下面给出对以上代码的解释:
· 给局部变量赋初值-ENOMEM,当分配一个新的task_struc结构失败时就返回这个错误值。
· 如果在clone_flags中设置了CLONE_PID标志,就返回一个错误(-EPERM)。因为CLONE_PID有特殊的作用,当这个标志为1时,父、子进程(线程)共用一个进程号,也就是说,子进程虽然有自己的task_struct结构,却使用父进程的pid。但是,只有0号进程(即系统中的空线程)才允许使用这个标志。
· 调用alloc_task_struct()为子进程分配两个连续的物理页面,低端用来存放子进程的task_struct结构,高端用作其内核空间的堆栈。
· 用结构赋值语句*p = *current把当前进程task_struct结构中的所有内容都拷贝到新进程中。稍后,子进程不该继承的域会被设置成正确的值。
· 在task_struct结构中有个指针user,用来指向一个user_struct结构。一个用户常常有多个进程,所以有关用户的信息并不专属于某一个进程。这样,属于同一用户的进程就可以通过指针user共享这些信息。显然,每个用户有且只有一个user_struct结构。该结构中有一个引用计数器count,对属于该用户的进程数量进行计数。可想而知,内核线程并不属于某个用户,所以其task_struct中的user指针为0。每个进程task_struct结构中有个数组rlim,对该进程占用各种资源的数量作出限制,而rlim[RLIMIT_NPROC]就规定了该进程所属用户可以拥有的进程数量。所以,如果当前进程是一个用户进程,并且该用户拥有的进程数量已经达到了规定的界限值,就不允许它fork()了。
· 除了检查每个用户拥有的进程数量外,接着要检查系统中的任务总数(所有用户的进程数加系统的内核线程数)是否超过了最大值max_threads,如果是,也不允许再创建子进程。
· 一个进程除了属于某个用户外,还属于某个“执行域”。 Linux可以运行X86平台上其它Unix类操作系统生成的符合iBCS2标准的程序。例如,一个进程所执行的程序是为Solaris开发的,那么这个进程就属于Solaris执行域PER_SOLARIS。当然,在Linux上运行的绝大多数程序属于Linux执行域。在task_struct有一个指针exec_doman,指向一个exec_doman结构。在exec_doman结构中有一个域是module,这是指向某个module结构的指针。在Linux中,一个文件系统或驱动程序都可以作为一个单独的模块进行编译,并动态地链接到内核中。在module结构中有一个计数器count,用来统计几个进程需要使用这个模块。因此,get_exec_domain(p->exec_domain)递增模块结构module中的计数器。
· 另外,每个进程所执行的程序属于某种可执行映像格式,如a.out格式、elf格式、甚至java虚拟机格式。对于不同格式的支持通常是通过动态安装的模块来实现的。所以,task_struct中有一个执行linux_binfmt结构的指针binfmt,而
__MOD_INC_USE_COUNT()就是对有关模块的使用计数进行递增。
· 紧接着为什么要把进程的状态设置成为TASK_UNINTERRUPTIBLE?这是因为后面get_pid()的操作必须独占,子进程可能因为一时进不了临界区而只好暂时进入睡眠状态。
· copy_flags()函数将clone_flags参数中的标志位略加补充和变换,然后写入p->flags。
· get_pid()函数根据clone_flags中标志位ClONE_PID的值,或返回父进程(当前进程)的pid,或返回一个新的pid。
· 前面在复制父进程的task_struct结构时把父进程的所有域都照抄过来,但实际上很多域的值必须重新赋初值,因此,后面的赋值语句就是对子进程task_struct结构的初始化。其中start_time表示进程创建的时间,而全局变量jiffies就是从系统初始化开始至当前的是时钟滴答数。local_pages表示属于该进程的局部页面形成一个双向链表,在此进行了初始化。
· copy_files()有条件地复制已打开文件的控制结构,也就是说,这种复制只有在clone_flags中的CLONE_FILES标志为0时才真正进行,否则只是共享父进程的已打开文件。当一个进程有已打开文件时,task_struct结构中的指针files指向一个fiel_struct结构,否则为0。所有与终端设备tty相联系的用户进程的头三个标准文件stdin、stdout及stderr都是预先打开的,所以指针一般不为空。
· copy_fs()也是只有在clone_flags中的CLONE_FS标志为0时才加以复制。在task_struct中有一个指向fs_struct结构的指针,fs_struct结构中存放的是进程的根目录root、当前工作目录pwd、一个用于文件操作权限的umask,还有一个计数器。类似地,copy_sighand()也是只有在CLONE_SIGHAND为0时才真正复制父进程的信号结构,否则就共享父进程的。信号是进程间通信的一种手段,信号随时都可以发向一个进程,就像中断随时都可以发向一个处理器一样。进程可以为各种信号设置相应的信号处理程序,一旦进程设置了信号处理程序,其task_struct结构中的指针sig就指向signal_struct结构(定义于include/linux/sched.h)。关于信号的具体内容将在下一章进行介绍。
· 用户空间的继承是通过copy_mm()函数完成的。进程的task_struct结构中有一个指针mm,就指向代表着进程地址空间的mm_struct结构。对mm_struct的复制也是在clone_flags中的CLONE_VM标志为0时才真正进行,否则,就只是通过已经复制的指针共享父进程的用户空间。对mm_struct的复制不只限于这个数据结构本身,还包括了对更深层次数据结构的复制,其中最主要的是vm_area_struct结构和页表的复制,这是由同一文件中的dum_mmap()函数完成的。
· 到此为止,task_struct结构中的域基本复制好了,但是用于内核堆栈的内容还没有复制,这就是copy_thread()的责任了。copy_thread()函数与平台相关,定义于arch/i386/kernel/process.c中。copy_thread()实际上只复制父进程的内核空间堆栈。堆栈中的内容记录了父进程通过系统调用fork()进入内核空间、然后又进入copy_thread()函数的整个历程,子进程将要循相同的路线返回,所以要把它复制给子进程。但是,如果父子进程的内核空间堆栈完全相同,那返回用户空间后就无法区分哪个是子进程了,所以,复制以后还要略作调整。有兴趣的读者可以结合第三、四章内容去读该函数的源代码。
· parent_exec_id表示父进程的执行域,p->self_exec_id是本进程(子进程)的执行域,swappable表示本进程的页面可以被换出。exit_signal为本进程执行exit()系统调用时向父进程发出的信号,pdeath_signal为要求父进程在执行exit()时向本进程发出的信号。另外,counter域的值是进程的时间片(以时钟滴达为单位),代码中将父进程的时间片分成两半,让父、子进程各有原值的一半。
· 进程创建后必须处于某一组中,这是通过task_struct结构中的队列头thread_group与父进程链接起来,形成一个进程组(注意,thread并不单指线程,内核代码中经常用thread通指所有的进程)。
· 建立进程的家族关系。先建立起子进程的祖先和双亲(当然还没有兄弟和孩子),然后通过SET_LINKS()宏将子进程的task_struct结构插入到内核中其它进程组成的双向链表中。通过hash_pid()将其链入按其pid计算得的哈希表中(参看第三章进程的组成方式一节)。
· 最后,通过wake_up_process()将子进程唤醒,也就是将其挂入可执行队列等待被调度。
· 但是,还有一种特殊情况必须考虑。当参数clone_flags中CLONE_VFORK标志位为1时,一定要保证子进程先运行,一直到子进程通过系统调用execve()执行一个新的可执行程序或通过系统调用exit()退出系统时,才可以恢复父进程的执行,这是通过wait_for_completion()函数实现的。为什么要这样做呢?这是因为当CLONE_VFORK标志位为1时,就说明父、子进程通过指针共享用户空间(指向相同的mm_struct结构),那也说明父进程写入用户空间的内容同时也写入了子进程的用户空间,反之亦然。如果说,在这种情况下,父子进程对数据区的写入可能引起问题的话,那么,对堆栈区的写入可能就是致命的了。而对子程序或函数的调用肯定就是对堆栈的写入。由此可见,在这种情况下,决不能让两个进程都回到用户空间并发执行,否则,必然导致两个进程的互相“捣乱”或因非法访问而死亡。解决的办法的只能是“扣留”其中的一个进程,而让另一个进程先回到用户空间,直到两个进程不再共享它们的用户空间,或其中一个进程消亡为止(肯定是先回到用户空间的进程先消亡)。
到此为止,子进程的创建已经完成,该是从内核态返回用户态的时候了。实际上,fork()系统调用执行之后,父子进程返回到用户空间中相同的的地址,用户进程根据fork()的返回值分别安排父子进程执行不同的代码。