与 Unix类似,Linux 中的程序和命令通常由命令解释器执行,这一命令解释器称为 shell。用户输入命令之后,shell 会在搜索路径(shell 变量PATH中包含搜索路径)指定的目录中搜索和输入命令匹配的映象(可执行的二进制代码)名称。如果发现匹配的映象,shell 负责装载并执行该映像。shell 首先利用 fork 系统调用建立子进程,然后用找到的可执行映象文件覆盖子进程正在执行的 shell 二进制映象。
可执行文件可以是具有不同格式的二进制文件,也可以是一个文本的脚本文件。可执行映象文件中包含了可执行代码及数据,同时也包含操作系统用来将映象正确装入内存并执行的信息。Linux 使用的最常见的可执行文件格式是 ELF 和 a.out,但理论上讲,Linux 有足够的灵活性可以装入任何格式的可执行文件。
1. ELF可执行文件
ELF 是“可执行可连接格式”的英文缩写,该格式由 Unix 系统实验室制定。它是 Linux 中最经常使用的格式,和其他格式(例如 a.out 或 ECOFF 格式)比较起来,ELF 在装入内存时多一些系统开支,但是更为灵活。ELF 可执行文件包含了可执行代码和数据,通常也称为正文和数据。这种文件中包含一些表,根据这些表中的信息,内核可组织进程的虚拟内存。另外,文件中还包含有对内存布局的定义以及起始执行的指令位置。
 下面我们分析一个简单程序在利用编译器编译并连接之后的 ELF 文件格式:
下面我们分析一个简单程序在利用编译器编译并连接之后的 ELF 文件格式:
#include <stdio.h>
main ()
{
printf(“Hello
world!\n”);
}
图6_24 所示,是上述源代码在编译连接后的 ELF 可执行文件的格式。从图
可以看出,ELF 可执行映象文件的开头是三个字符 ‘E’、‘L’ 和 ‘F’,作为这类文件的标识符。e_entry 定义了程序装入之后起始执行指令的虚拟地址。这个简单的 ELF 映象利用两个“物理头”结构分别定义代码和数据,e_phnum 是该文件中所包含的物理头信息个数,本例为 2。e_phyoff 是第一个物理头结构在文件中的偏移量,而e_phentsize 则是物理头结构的大小,这两个偏移量均从文件头开始算起。根据上述两个信息,内核可正确读取两个物理头结构中的信息。
物理头结构的
p_flags 字段定义了对应代码或数据的访问属性。图中第一个 p_flags 字段的值为 FP_X 和 FP_R,表明该结构定义的是程序的代码;类似地,第二个物理头定义程序数据,并且是可读可写的。p_offset 定义对应的代码或数据在物理头之后的偏移量。p_vaddr 定义代码或数据的起始虚拟地址。p_filesz
和 p_memsz 分别定义代码或数据在文件中的大小以及在内存中的大小。对我们的简单例子,程序代码开始于两个物理头之后,而程序数据则开始于物理头之后的第 0x68533 字节处,显然,程序数据紧跟在程序代码之后。程序的代码大小为
0x68532,显得比较大,这是因为连接程序将 C 函数
printf 的代码连接到了 ELF 文件的原因。程序代码的文件大小和内存大小是一样的,而程序数据的文件大小和内存大小不一样,这是因为内存数据中,起始的 2200 字节是预先初始化的数据,初始化值来自 ELF 映象,而其后的 2048 字节则由执行代码初始化。
如前面所描述的,Linux 利用请页技术装入程序映象。当 shell 进程利用 fork ()系统调用建立了子进程之后,子进程会调用 exec ()系统调用(实际有多种 exec 调用),exec() 系统调用将利用 ELF
二进制格式装载器装载 ELF 映象,当装载器检验映象是有效的 ELF 文件之后,就会将当前进程(实际就是父进程或旧进程)的可执行映象从虚拟内存中清除,同时清除任何信号处理程序并关闭所有打开的文件(把相应 file 结构中的 f_count 引用计数减 1,如果这一计数为 0,内核负责释放这一文件对象),然后重置进程页表。完成上述过程之后,只需根据 ELF 文件中的信息将映象代码和数据的起始和终止地址分配并设置相应的虚拟地址区域,修改进程页表。这时,当前进程就可以开始执行对应的 ELF 映象中的指令了。
2.命令行参数和shell环境
当用户敲入一个命令时,从shell可以接受一些命令行参数。例如,当用户敲入命令:
$ ls -l /usr/bin
以获得在/usr/bin目录下的全部文件列表时,shell进程创建一个新进程执行这个命令。这个新进程装入/bin/ls可执行文件。在这样做的过程中,从shell继承的大多数执行上下文被丢弃,但三个单独的参数ls、-l和 /usr/依然被保持。一般情况下,新进程可以接受任意个参数。
传递命令行参数的约定依赖于所用的高级语言。在C语言中,程序的main( )函数把传递给程序的参数个数和指向字符串指针数组的地址作为参数。下面是main()的原型:
int main(int argc, char *argv[])
再回到前面的例子,当/bin/ls程序被调用时,argc的值为3,argv[0]指向ls字符串,argv[1]指向-l字符串,而argv[2]指向 /usr/bin字符串。argv数组的末尾处总以空指针来标记,因此,argv[3]为NULL。
在C语言中传递给main()函数的第三个可选参数是包含环境变量的参数。当进程用到它时,main( )的声明如下:
int main(int argc, char *argv[], char *envp[])
envp参数指向环境串的指针数组,形式如下:
VAR_NAME=something
在这里,VAR_NAME表示一个环境变量的名字,而“=”后面的子串表示赋给变量的实际值。envp数组的结尾用一个空指针标记,就像argv数组。环境变量是用来定制进程的执行上下文、为用户或其它进程提供一般的信息、或允许进程交叉调用execve( )系统调用保存一些信息。
PAGE_OFFSET env_end env_start arg_sart &envp[0] &argv[0] start_stack
命令行参数和环境串都放在用户态堆栈。图6.25显示了用户态堆栈底部所包含的内容。注意环境变量位于栈底附近正好在一个null的长整数之后。
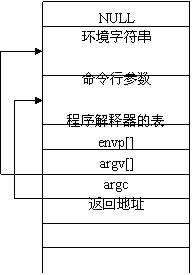
图6.25 用户态堆栈底部所包含的内容
3.函数库
每个高级语言的源代码文件都是经过几个步骤才转化为目标文件的,目标文件中包含的是汇编语言指令的机器代码,它们和相应的高级语言指令对应。目标文件并不能被执行,因为它不包含源代码文件所用的全局外部符号名的虚拟地址。这些地址的分配或解析是由链接程序完成的,链接程序把程序所有的目标文件收集起来并构造可执行文件。链接程序还分析程序所用的库函数并把它们粘合成可执行文件。
任何程序,甚至最小的程序都会利用C库。请看下面的一行C程序:
void main(void) { }
尽管这个程序没有做任何事情,但还是需要做很多工作来建立执行环境并在程序终止时杀死这个进程。尤其是,当main( )函数终止时,C编译程序就把exit( )系统调用插入到目标代码中。
实际上,一般程序对系统调用的调用通常是通过C库中的封装例程进行的,也就是说,C语言函数库中的函数先调用系统调用,而我们的应用程序再调用库函数。除了C库,Unix系统中还包含很多其它的函数库。一般的Linux系统可能轻而易举地就有50个不同的库。这里仅仅列举其中的两个:数学库libm包含浮点操作的基本函数,而X11库libX11收集了所有X11窗口系统图形接口的基本底层函数。
传统Unix系统中的所有可执行文件都是基于静态库的。这就意味着链接程序所产生的可执行文件不仅包括原程序的代码,还包括程序所引用的库函数的代码。
静态库的一大缺点是:它们占用大量的磁盘空间。的确,每个静态链接的可执行文件都复制库代码的一部分。因此,现代Unix系统利用了共享库。可执行文件不用再包含库的目标代码,而仅仅指向库名。当程序被装入内存执行时,一个叫做程序解释器的程序就专注于分析可执行文件中的库名,确定所需库在系统目录树中的位置,并使执行进程可以使用所请求的代码。
共享库对提供文件内存映射的系统尤为方便,因为它们减少了执行一个程序所需的主内存量。当程序解释器必须把某一共享库链接到进程时,并不拷贝目标代码,而是仅仅执行一个内存映射,把库文件的相关部分映射到进程的地址空间中。这就允许共享库机器代码所在的页面由使用相同代码的所有进程进行共享。
共享库也有一些缺点。动态链接的程序启动时间通常比静态链接的长。此外,动态链接的程序的可移植性也不如静态链接的好,因为当系统中所包含的库版本发生变化时,动态链接的程序可能就不能适当地执行。
用户可以让一个程序静态地链接。例如,GCC编译器提供-static选项,即告诉链接程序使用静态库而不是共享库。
和静态连接库不同,动态连接库只有在运行时才被连接到进程的虚拟地址中。对于使用同一动态连接库的多个进程,只需在内存中保留一份共享库信息即可,这样就节省了内存空间。当共享库需要在运行时连接到进程虚拟地址时,Linux 的动态连接器利用 ELF 共享库中的符号表完成连接工作,符号表中定义了 ELF 映象引用的全部动态库例程。Linux
的动态连接器一般包含在 /lib 目录中,通常为
ld.so.1、llibc.so.1 和ld-linux.so.1。