在执行fork()之后,同一进程有两个拷贝都在运行,也就是说,子进程具有与父进程相同的可执行程序和数据(简称映像)。但是,子进程肯定不满足于仅仅成为父进程的“影子”,因此,父进程就要调用execve()装入并执行子进程自己的映像。execve()函数必需定位可执行文件的映像,然后装入并运行它。当然开始装入的并不是实际二进制映像的完全拷贝,拷贝的完全装入是用请页装入机制(demand pageing loading)逐步完成的。开始时只需要把要执行的二进制映像头装入内存,可执行代码的 inode 节点被装入当前进程的执行域中就可以执行了
。
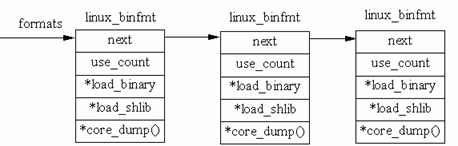
由于Linux文件系统采用了linux_binfmt数据结构(在/include/linux/ binfmt.h中,见文件系统注册)来支持各种文件系统,所以Linux中的exec()函数执行时,使用已注册的linux_binfmt结构就可以支持不同的二进制格式,即多种文件系统(EXT2,dos等)。需要指出的是binux_binfmt结构中嵌入了两个指向函数的指针,一个指针指向可执行代码,另一个指向了库函数;使用这两个指针是为了装入可执行代码和要使用的库。 linux_binfmt结构描述如下,其链表结构的示意图如图6.26所示:
struct linux_binfmt {
struct linux_binfmt * next;
long *use_count;
int
(*load_binary)(struct linux_binprm *, struct pt_regs * regs);/*装入二进制代码*/
int
(*load_shlib)(int fd); /*装入公用库*/
int (*core_dump)(long signr, struct pt_regs * regs);
};
图6.26 linux_binfmt的链表结构
在使用这种数据结构前必须调用vod binfmt_setup()函数进行初始化;这个函数分别初始化了一些可执行的文件格式,如:init_elf_binfmt();init_aout_binfmt();init_java_binfmt();init_script_binfmt())。
其实初始化就是用register_binfmt(struct linux_binfmt * fmt)函数把文件格式注册到系统中,即加入*formats所指的链中,*formats的定义如下:
static struct linux_binfmt *formats = (struct linux_binfmt *)
NULL
在使用装入函数的指针时,如果可执行文件是ELF格式的,则指针指向的装入函数分别是:
load_elf_binary(struct
linux_binprm * bprm, struct pt_regs * regs);
static int load_elf_library(int fd);
所以elf_format文件格式说明将被定义成:
static struct linux_binfmt elf_format = {#ifndef MODULE
NULL,
NULL, load_elf_binary, load_elf_library, elf_core_dump#else
NULL,
&mod_use_count_, load_elf_binary, load_elf_library, elf_core_dump#endif }
其他格式文件处理很类似,相关代码请看本节后面介绍的search_binary_handler()函数。
另外还要提的,在装入二进制时还需要用到结构linux_binprm,这个结构保存着一些在装入代码时需要的信息:
struct linux_binprm{
char
buf[128];/*读入文件时用的缓冲区*/
unsigned long
page[MAX_ARG_PAGES];
unsigned long p;
int sh_bang;
struct inode * inode;/*映像来自的节点*/
int e_uid,
e_gid;
int
argc, envc; /*参数数目,环境数目*/
char * filename; /* 二进制映像的名字,也就是要执行的文件名 */
unsigned long
loader, exec;
int dont_iput; /* binfmt handler has put
inode */
};
其它域的含义在后面的do_exec()代码中做进一步解释。
Linux所提供的系统调用名为execve(),可是,C语言的程序库在此系统调用的基础上向应用程序提供了一整套的库函数,包括execve()、execlp()、execle()、execv()、execvp(),它们之间的差异仅仅是参数的不同。下面来介绍execve()的实现。
系统调用execve()在内核的入口为sys_execve(),其代码在arch/i386/kernel/process.c:
/*
* sys_execve() executes a new program.
*/
asmlinkage int sys_execve(struct pt_regs regs)
{
int error;
char * filename;
filename = getname((char *) regs.ebx);
error = PTR_ERR(filename);
if (IS_ERR(filename))
goto out;
error = do_execve(filename, (char **) regs.ecx, (char **)
regs.edx, ®s);
if (error == 0)
current->ptrace &= ~PT_DTRACE;
putname(filename);
out:
return error;
}
系统调用进入内核时,regs.ebx中的内容为应用程序中调用相应的库函数时的第一个参数,这个参数就是可执行文件的路径名。但是此时文件名实际上存放在用户空间中,所以getname()要把这个文件名拷贝到内核空间,在内核空间中建立起一个副本。然后,调用do_execve()来完成该系统调用的主体工作。do_execve()的代码在fs/exec.c中:
/*
* sys_execve() executes a new program.
*/
int do_execve(char * filename, char ** argv, char ** envp,
struct pt_regs * regs)
{
struct linux_binprm bprm;
struct file *file;
int retval;
int i;
file = open_exec(filename);
retval = PTR_ERR(file);
if (IS_ERR(file))
return retval;
bprm.p = PAGE_SIZE*MAX_ARG_PAGES-sizeof(void
*);
memset(bprm.page, 0,
MAX_ARG_PAGES*sizeof(bprm.page[0]));
bprm.file = file;
bprm.filename = filename;
bprm.sh_bang = 0;
bprm.loader = 0;
bprm.exec = 0;
if ((bprm.argc = count(argv, bprm.p /
sizeof(void *))) < 0) {
allow_write_access(file);
fput(file);
return bprm.argc;
}
if ((bprm.envc = count(envp, bprm.p /
sizeof(void *))) < 0) {
allow_write_access(file);
fput(file);
return bprm.envc;
}
retval = prepare_binprm(&bprm);
if (retval < 0)
goto out;
retval = copy_strings_kernel(1, &bprm.filename,
&bprm);
if (retval < 0)
goto out;
bprm.exec = bprm.p;
retval = copy_strings(bprm.envc, envp,
&bprm);
if (retval < 0)
goto out;
retval = copy_strings(bprm.argc, argv, &bprm);
if (retval < 0)
goto out;
retval = search_binary_handler(&bprm,regs);
if (retval >= 0)
/* execve success */
return retval;
out:
/* Something went
wrong, return the inode and free the argument pages*/
allow_write_access(bprm.file);
if (bprm.file)
fput(bprm.file);
for (i = 0 ; i < MAX_ARG_PAGES ; i++) {
struct page * page = bprm.page[i];
if (page)
__free_page(page);
}
return retval;
}
参数filename,argv,envp分别代表要执行文件的文件名,命令行参数及环境串。下面对以上代码给予解释:
· 首先,将给定可执行程序的文件找到并打开,这是由open_exec()函数完成的。open_exec()返回一个file结构指针,代表着所读入的可执行文件的映像。
· 与可执行文件路径名的处理办法一样,每个参数的最大长度也定为一个页面(是否有点浪费?),所有linux_binprm结构中有一个页面指针数组,数组的大小为系统所允许的最大参数个数MAX_ARG_PAGES(定义为32)。memset()函数将这个指针数组初始化为全0。
· 对局部变量bprm的各个域进行初始化。其中bprm.p几乎等于最大参数个数所占用的空间; bprm.sh_bang表示可执行文件的性质,当可执行文件是一个Shell脚本(Shell Sript)时置为1,此时还没有可执行Shell脚本,因此给其赋初值0,还有其它两个域也赋初值0。
· 函数count()对字符串数组argv[]中参数的个数进行计数。bprm.p / sizeof(void *)表示所允许参数的最大值。同样,对环境变量也要统计其个数。
· 如果count()小于0,说明统计失败,则调用fput()把该可执行文件写回磁盘,在写之前,调用allow_write_access()来防止其他进程通过内存映射改变该可执行文件的内容。
· 完成了对参数和环境变量的计数之后,又调用prepare_binprm()对bprm变量做进一步的准备工作。更具体地说,就是从可执行文件中读入开头的128个字节到linux_binprm结构的缓冲区buf,这是为什么呢?因为不管目标文件是elf格式还是a.out格式,或者其它格式,在其可执行文件的开头128个字节中都包括了可执行文件属性的信息,如图6.24。
· 然后,就调用copy_strings把参数以及执行的环境从用户空间拷贝到内核空间的bprm变量中,而调用copy_strings_kernel()从内核空间中拷贝文件名,因为前面介绍的get_name()已经把文件名拷贝到内核空间了。
· 所有的准备工作已经完成,关键是调用search_binary_handler()函数了,请看下面对这个函数的详细介绍。
search_binary_handler()函数也在exec.c中。其中有一段代码是专门针对alpha处理器的条件编译,在下面的代码中跳过了这段代码:
/*
* cycle the
list of binary formats handler, until one recognizes the image
*/
int search_binary_handler(struct linux_binprm
*bprm,struct pt_regs *regs)
{
int try,retval=0;
struct linux_binfmt *fmt;
6 #ifdef __alpha__
…..
#endif
/* kernel module loader fixup */
/* so we don't try to load run modprobe in kernel space. */
set_fs(USER_DS);
for (try=0; try<2; try++) {
read_lock(&binfmt_lock);
for (fmt = formats ; fmt ; fmt = fmt->next)
{
int (*fn)(struct linux_binprm *, struct pt_regs
*) = fmt->load_binary;
if (!fn)
continue;
if (!try_inc_mod_count(fmt->module))
continue;
read_unlock(&binfmt_lock);
retval = fn(bprm, regs);
if (retval >= 0) {
put_binfmt(fmt);
allow_write_access(bprm->file);
if (bprm->file)
fput(bprm->file);
bprm->file = NULL;
current->did_exec = 1;
return retval;
}
read_lock(&binfmt_lock);
put_binfmt(fmt);
if (retval != -ENOEXEC)
break;
if (!bprm->file) {
read_unlock(&binfmt_lock);
return retval;
}
}
read_unlock(&binfmt_lock);
if (retval != -ENOEXEC) {
break;
#ifdef CONFIG_KMOD
}else{
#define printable(c) (((c)=='\t') || ((c)=='\n') || (0x20<=(c) &&
(c)<=0x7e))
char modname[20];
if (printable(bprm->buf[0]) &&
printable(bprm->buf[1]) &&
printable(bprm->buf[2]) &&
printable(bprm->buf[3]))
break; /* -ENOEXEC */
sprintf(modname, "binfmt-%04x", *(unsigned short
*)(&bprm->buf[2]));
request_module(modname);
#endif
}
}
return retval;
}
在exec.c中定义了一个静态变量formats:
static struct linux_binfmt *formats
因此,formats就指向图6.26中链表队列的头,挂在这个队列中的成员代表着各种可执行文件格式。在do_exec()函数的准备阶段,已经从可执行文件头部读入128字节存放在bprm的缓冲区中,而且运行所需的参数和环境变量也已收集在bprm中。search_binary_handler()函数就是逐个扫描formats队列,直到找到一个匹配的可执行文件格式,运行的事就交给它。如果在这个队列中没有找到相应的可执行文件格式,就要根据文件头部的信息来查找是否有为此种格式设计的可动态安装的模块,如果有,就把这个模块安装进内核,并挂入formats队列,然后再重新扫描。下面对具体程序给予解释:
· 程序中有两层嵌套for循环。内层是针对formats队列的每个成员,让每一个成员都去执行一下load_binary()函数,如果执行成功,load_binary()就把目标文件装入并投入运行,并返回一个正数或0。当CPU从系统调用execve()返回到用户程序时,该目标文件的执行就真正开始了,也就是,子进程新的主体真正开始执行了。如果load_binary()返回一个负数,就说明或者在处理的过程中出错,或者没有找到相应的可执行文件格式,在后一种情况下,返回-ENOEXEC。
· 内层循环结束后,如果load_binary()执行失败后的返回值为-ENOEXEC,就说明队列中所有成员都不认识目标文件的格式。这时,如果内核支持动态安装模块(取决于编译选项CONFIG_KMOD),就根据目标文件的第2和第3个字节生成一个binfmt模块,通过request_module()试着将相应的模块装入内核(参见第十章)。外层的for循环有两次,就是为了在安装了模块以后再来试一次。
· 在linux_binfmt数据结构中,有三个函数指针:load_binary、load_shlib以及core_dump,其中load_binary就是具体的装载程序。不同的可执行文件其装载函数也不同,如a.out格式的装载函数为load_aout_binary(),elf的装载函数为load_elf_binary(),其源代码分别在fs/binfmt_aout.c中和fs/binfmt_elf中。有兴趣的读者可以继续探究下去。
本章从内存的初始化开始,分别介绍了地址映射机制、内存分配与回收机制、请页机制、交换机制、缓存和刷新机制、程序的创建及执行等八个方面。可以说,内存管理是整个操作系统中最复杂的一个子系统,因此,本章用大量的篇幅对相关内容进行了介绍,即使如此,也仅仅介绍了主要内容。
在本章的学习中,有一点需特别向读者强调。在Linux系统中,CPU不能按物理地址访问存储空间,而必须使用虚拟地址。因此,对于Linux内核映像,即使系统启动时将其全部装入物理内存,也要将其映射到虚拟地址空间中的内核空间,而对于用户程序,其经过编译、链接后形成的映像文件最初存于磁盘,当该程序被运行时,先要建立该映像与虚拟地址空间的映射关系,当真正需要物理内存时,才建立地址空间与物理空间的映射关系。