ELK大数据与威胁日志的数据迁徙方法
作者:糖果
0×01 概要
接上次ClickHouse威胁日志分析那篇接着写,这次是我们要把已经存储于ES集群中的相关日志和威胁情报转存ClickHouse上,整体分三部分来说,一部分记逻辑和物理上Graylog是如何处理日志数据。第二部分是写ClickHouse在物理部署和逻辑流程上是如何处理数据,第三部分讲如何这种体系的数据系统进行对接,Graylog相关的这部分内容官网也会讲,但不会在讲在这种使用场景下的处理流程,只当讲Graylog本身的小型或是大一些规模的存储结构。
0×02 Graylog的日志收集与存储结构
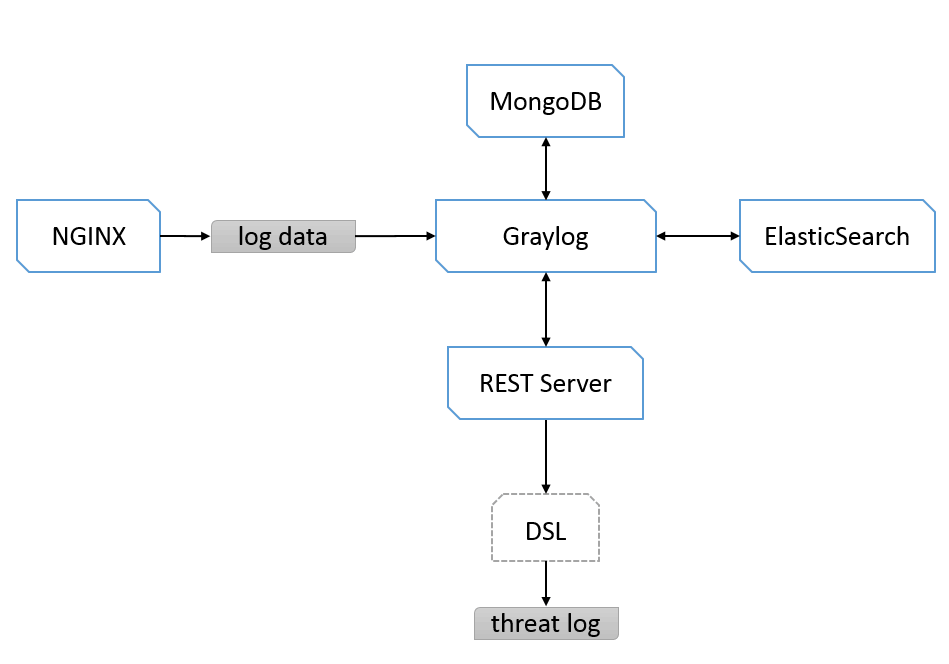
上面图就是比较典型处理结构,从最始的Nginx端口来发送Syslog日志数据给Graylog,Graylog把推送过来的数据按装Stream的单位按索引存储到ES中,我们通过配置MongoDB来控制Graylog的配置,Graylog提供了一个REST API的Server服务,对外开发根据DSL方式的日志查询,有Stream就有跨Stream查询,这样来说就实现的跨索引的关联查询。我们通过REST API实现更复系统实现和可视化实现,这也是对Graylog最小化系统结构的一种简单描述。
0×03 比ES更高级的抽象结构
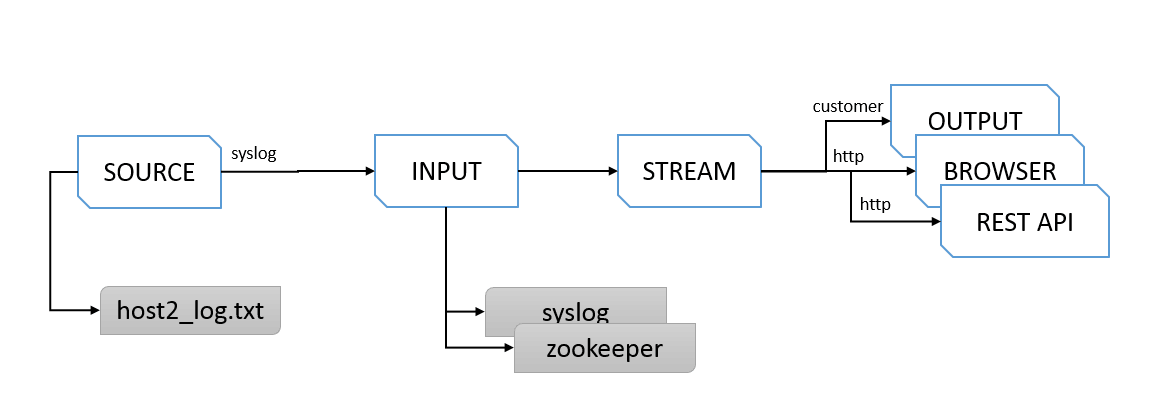
Graylog抽象出了Input、stream、output这些概念,并且在Pipeline的设计思想下运作,通过提供私用的一种检索的DSL语言, 让跨索引查询更方便,逻辑上把不同的Source比如不同Openresty服务器上的日志定义成Input,再把指定的Input设定给Stream,通过管理Stream的Output指向日志数据的流向, 可以是syslog,kafka等其它系统可以接入的形式,也可以不定义OUTPUT,直接通过浏览器进行查询,或是通过暴露REST API对外提供查询数据。
0×04 Graylog的输出模式
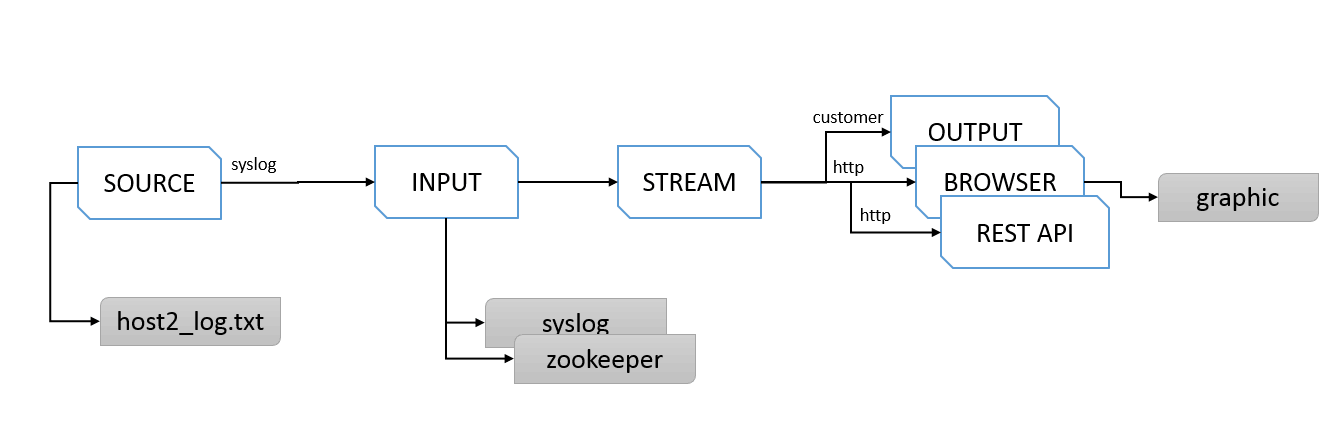
我们再说定义output到kafka,再到ClickHouse之前介绍的就是Graylog可以直接通过浏览器,提供图型化的聚合和日志查询。
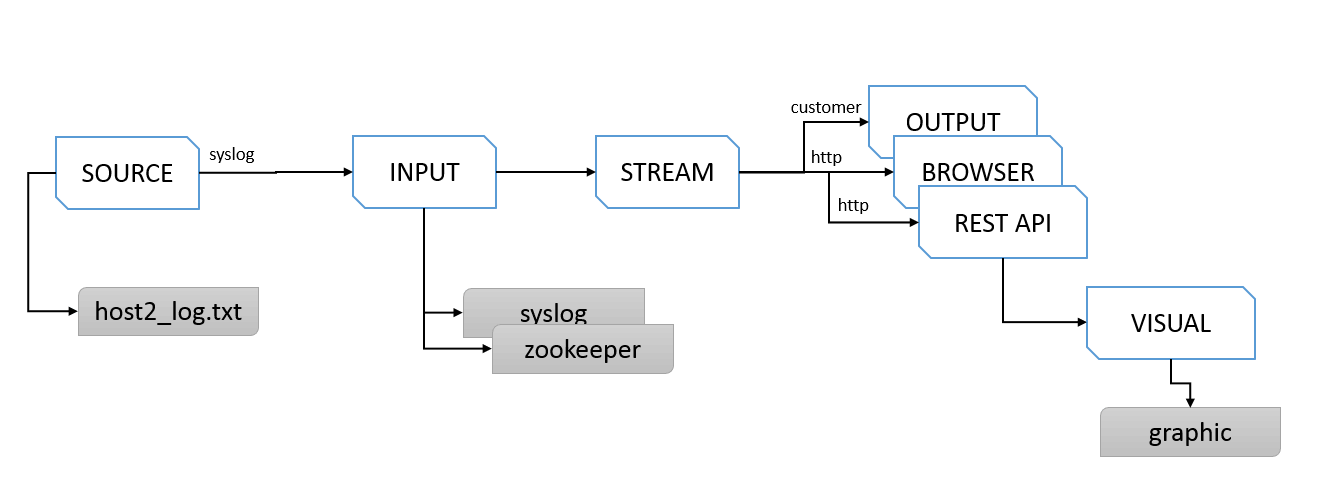
Graylog也可以通过REST服务,给第三入接入系统提供更丰富的可视化数据源。
0×05 ClickHouse日志收集的最小化模式

讲了Graylog的基础日数据处理流程,我们再来看看最小的Kafka系统是如何处理数据的,Nginx通过kafkacat这种工具,把日志数据推送到Kafka上,然后由消费者消费数据,建立一个缓存机制写入到ClickHouse里,这个之前都有说过,我们再通过SQL文的方式去ClickHouse中取数数据,得到我们想到的威胁日志。
0×06 Graylog到ClickHouse传送门
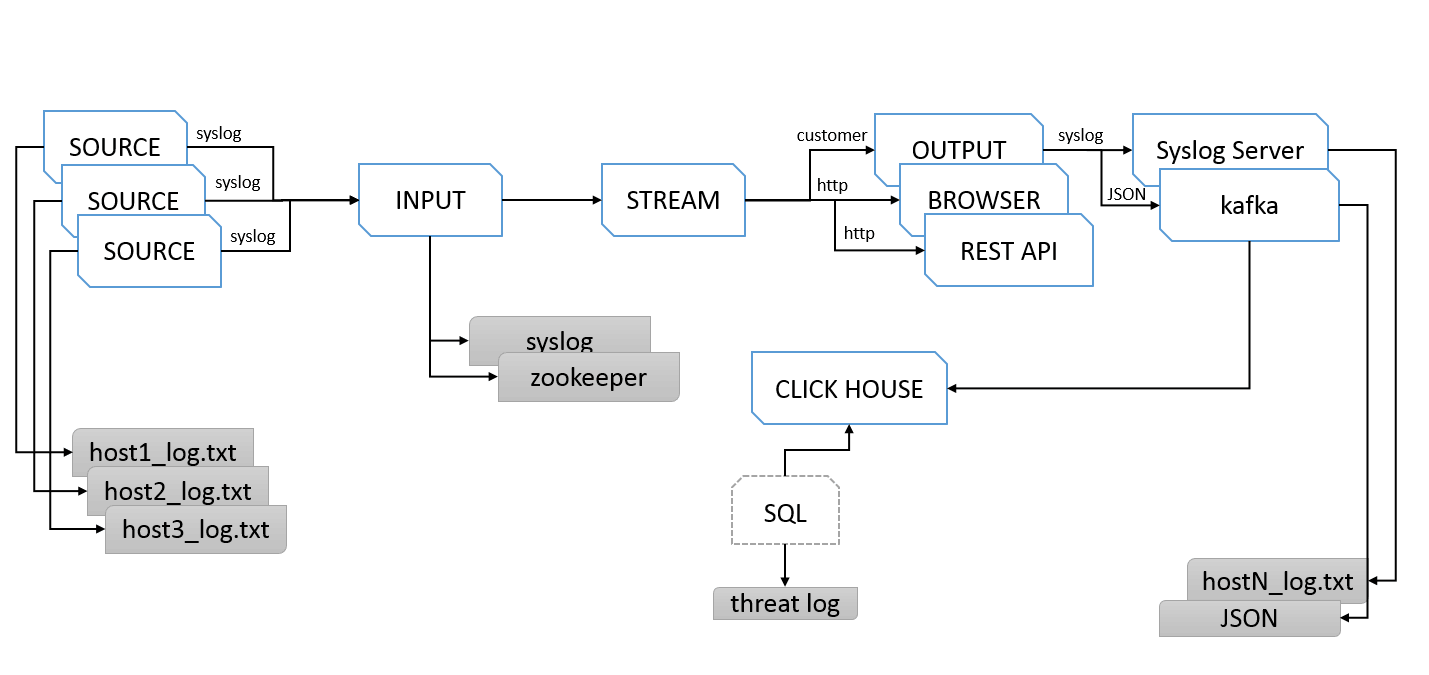
我们从数据流向来看如何从Graylog将数据传送到ClickHouse的一个整体流程, 我们通过把不同Source来源的日志通过Syslog指定传给Graylog的Syslog接收端口,收集到指定的Input单元,然后在Graylog中创建Stream选出之前创建的Input,然后在创建的Stream中创建或是选取一个指定的Output设定,我们把Output指定输出的目标指向到Kafka服务地址上,这个阶段Graylog完成了日志数据的收集到格式整弄,再到最后一步的转发。 当Kafka上产生数据后,消费者读取数据写入到ClickHouse,通过SQL实现数据的聚合和查询。完成了整个数据处理流程 。
0×07 总结
通过以上的方式我们可以收集分布在不同位置服务器上的日志数据,可以用Graylog进行跨索引查询,可能通用ClickHouse对大数据日志进行实时的检索和聚合分析,通过ClilckHouse实验做行为画像分析。