日志分析系统与小语言DSL的WAF的结合使用
作者:糖果
基于Openresty构建的服务日益受欢迎, WAF作为一个典型的上的应用,在过去的一段时间内经常在社区和人们的视野中出现。这些应用都会涉及到一些共通性的问题,和底层有关的比如性能问题,和基础服务有关的比如Openresty提供的API,和应用业务有关的比如地策略规则的问题,和验证有关的大数据日志存储,展开具体说一下相关内容。
1.基于正则的匹配。
防火墙系统核心的一个功能就是策略相关的威胁检索引擎,因为WAF是7层的应用,直接针对的HTTP协议的数据,基于正则的检索引擎主要考底层的库来支持,目前来看这库主要是二种,一种是LUA本身支持的一种正侧,像Loveshell系的WAF用的都是这种正则表达式在规则定义中,另外一种就是典型的PCRE标谁库。 基于正则的检索本身是很耗费资源的,要想实质性的优化这部分的性能,首先把控本身代码的效率,使用列符合jit凡是的代码,但最主要的性能改善,主要还是要靠正则库本身的效率的提升级。
最近比较值得关注的不是社区的基于大型流数据正则检索引擎sregex。如果lua本身的执行效率特高了,正则引擎的效率都提高了,WAF的本身也就提高了。
2.配置规则下发。
云WAF这种部署型式基本上使用的是集群的方式。集群多少都要与负载均衡对接,涉及到规则文件下发的问题,一般情况如果规则缓存在共享字典中在,是不需要重起nginx服务的,只有个修改了conf本身才会涉及到重起nginx服务的问题。传统的做法是定时器定时的刷新规则文本和或是mysql数据库,来刷新新产生部署下规则,这样规则被存在中心服务器当中心定时拉取。 随着Openrest+这种服务出现,基于之上的服务器,服务器集群的下发可能将采取长链接的形式,主控服务器与结点之间维持长链接通信,发布后会以很快的速度到达结点服务器,这是与之前的传统的服务有很大不同的地方。如果你只是想注意力放到你的业务上,而不是业务规则的实现上,或是更高的追求:“让人类专注于表达和管理业务领域的知识”。
最新版的Openresty支持HTTP流量镜像,我们可以从7层支持复制流量到监控机上,这样结点就可以直接用数据中心结点取数据,不影响中断业务,但是这样没有做到去中心化问题。
3.策略规则描述语言发生改变。
传统基于Nginx+lua、Openresty这种WAF的策略规则,有的基于简单文本的正则,有的是基于JSON形式存储的规则语言语议表达。最初基于文本的都是文本文件分类的规则分组,不同的文件分组不同的策略,有的简单的正则,有的是定义了策略和相应响应执行动作的定义。 JSON形式存储的语义更丰富,想存什么和业务有关的数据都可以自由的想象。之前规则多数是一种策略规则数据的定义,策略规则的定义和命中响应的动作内容是定义在一起的,策略定义和策略命中后具体实际执行的动作是分开的,数据定义只是一个数据结构,不是一个程序或DSL,把数据结构的定义和对数据结构的操作放在一起,经过编译或是解释翻译,还是作为LUA程序的输入存在。如果将策略有一种和业务相关DSL来描述, 这样的抽象程度更好, DSL更像一个小型的高级语言,DSL小型的领务业务语言更适合,更接近人思维的自然语言。并且小语言和策略有一个区分的标志是小语言可以上下文中存在变量的定义和通过变量传统状态。用一个策略规则影响另外一个策略规则的执行。
4.大数据协查与验证。
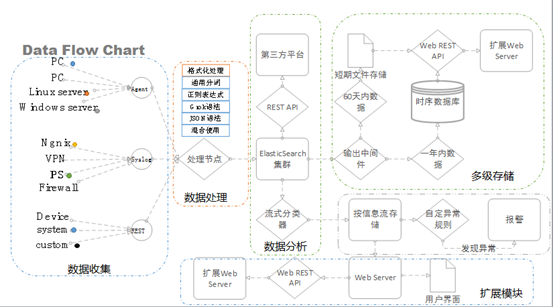
WAF进行实时的拦截,是针对HTTP实进请求过程中的数据包进行分析的,而基于大数据分析WAF是基于流量日志的。基于Openresty+LUA的WAF看到的是实时7层HTTP流量监听,而大数据分析是将Nginx、Openresty这种WEB的服务流地存储,用KafkaCat、RESTY-Kafka、RESTY-ElasticSearch这些日志数据的进行汇总放到队列上,或是采用分光、VSS等流量镜像的方式从网络层获取7层的数据,然后进行并行集中分析存处理,这种模式的好处是不影响服务的响应,基础服务的构建成本,需要人维护ZK、kafka、这些服务组件。在拦截上执行上,可用iptable或是nginx+lua只拦截不分析的模式,进行攻击拦截。并行处理虽然有延时,但还是相对准实时,间隔时间短的发现威胁。日志分析是基于统计算法的,即使是深度学习,也是要积累数据。
如果想降低整体系的运维成本,可以使用打包的开源方案,或是企业方案。日志汇聚典型的开源工具是graylog,与其对应的商用产品就是 splunk,graylog本身也有商业企业版,提供更好的服务。使用体验上和ELK像,整体模式,还是先流量监听,数据收集,集中分析,威胁情报,威胁策略关联配对,威胁可视化这些内容,并且他们可以集成其它产品作再次的分析,比如splunk可以读取tenable的pvs事件,或是Paloalto等推送的威胁。在应用管理上splunk这种商业产品就要比graylog的使用体验上要好一些。Graylog本身提供kakfa、mongodb、ES集群这些服务的整合,提供Rest API服务接口,提供日志收集终端。可以自己通过调用接口与echarts进行可视化展示,也可以用granfana这些工具进行联动展示。

说了这些和WAF有什么关系呢?如何验证WAF是否有效,如何进行误报率和漏报率的统计呢? 轻则pcap流量,重则日志落体存储,如何统计某时间段IP的TOP10流理排名呢?日志统计可以做到,就用日志用统计,然后呢?然后针对某些特征做拦截,做限速,做定时封禁。更理想的状态时,这种流量的统计直接在WAF算出TopX,然后对TopX的IP流理大户进行判断,如果这范围之内发现可疑IP,就用这一组群的IP进行限速。
5.常见威胁处理案例
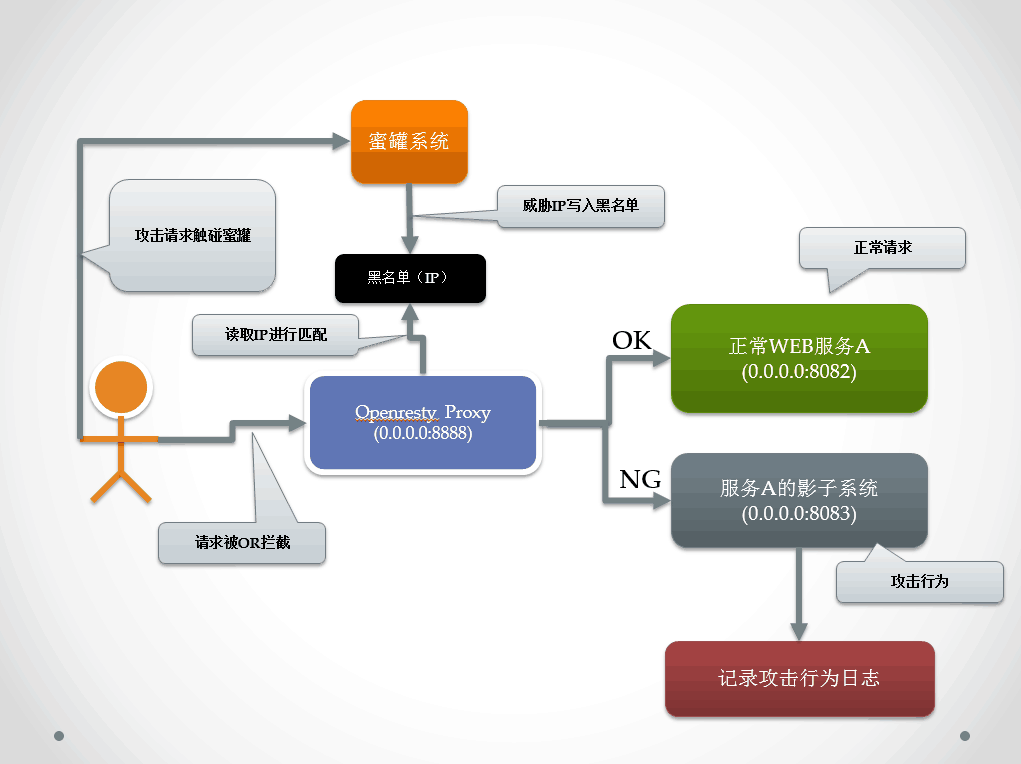
5-1.影子蜜罐: 我们再次提到了这个系统,在XWAF中 有一种工作模式叫做精华水月模式,就是利用WAF和蜜罐系统,当发现时威胁攻击时,直接将流量引到蜜罐上收集攻击的服务。
如果命名用LUA来这段策略叫配置修改conf文件,还要对应写出切换upstream的逻辑,如果用DSL描述这个策略:
uri contains “SQL”=>
set-upstream(‘HoneyPot_1′);
req-header(“Content-Type”) contains “multipart/form-data”,
req-header(“Content-Type”) !contains rx{^multipart/form-data[\s\S]+} =>
waf-mark-evil(message: “CVE-2017-5638 Struts”, level: “super”),
set-upstream(‘HoneyPot_2′);
5-2 CC防护
如是用传统的JS也可以对这个某些用户和IP进行限速,如果用 edge描述这个策略:
这个是限制请求速度,以及返回数据的速度,里面包括了 IP 和是否移动端的判断:
uri(“/shop”), client-province(‘Guangdong’),
ua-is-mobile() =>
limit-req-rate(key: client-addr, target-rate: 5 [r/s], reject-rate: 10 [r/s]), limit-resp-data-rate(441 [mB/s]);
延迟返回
uri(“/shop”), client-country(“US”) =>
limit-req-rate(key: client-addr, target-rate: 5 [r/s], reject-rate: 10 [r/s]), sleep(0.5);
6.总结
我们结合流量监听、日志汇聚分析、edge 小语言的结合使用,使用的部分的开源解决方案,来解决的具体问题,比较传统的与传统基于纯lua的waf的区别,提到了最新nginx-mirror,规则下发同步问题, honeypot的联合影子系统, 这里最主要的差异是DSL高度抽象了业务,让安全人员更多的关注策略表达,而不是代码更大的lua实现,和要考虑到各种配置的七层HTTP操作,解放了一部分生产力,提高了效率。如果openresty本身提供了流量度量,WAF集群又可以脱离日志分析中心,直接参于CC防护,作为防护算法的一部分,有一些列高级的功能还没在社区的开发中,因为底层服务的改变,基于openresty、nginx的WAF设计也会随着时间和新特性的加入,而继续发生变革。