网站服务的监控自动恢复与安全防护部署
作者:糖果
0×01 概要
服务的稳定性和安全性是我们平时都要关注的,在服务器可用性达标的前提下,我们还要保证服务的安全性。如何服务本身已经不可能用,安全性也无从谈起了,再安全也不能通过拔服务器性电源保证服务的安全性,安全性对可用性来说是唇寒齿亡的关系,可用性对安全性来说,是后者存在的前提。
0×02 常用系统构成
我们先看看一般服务的系统构成,如下图:
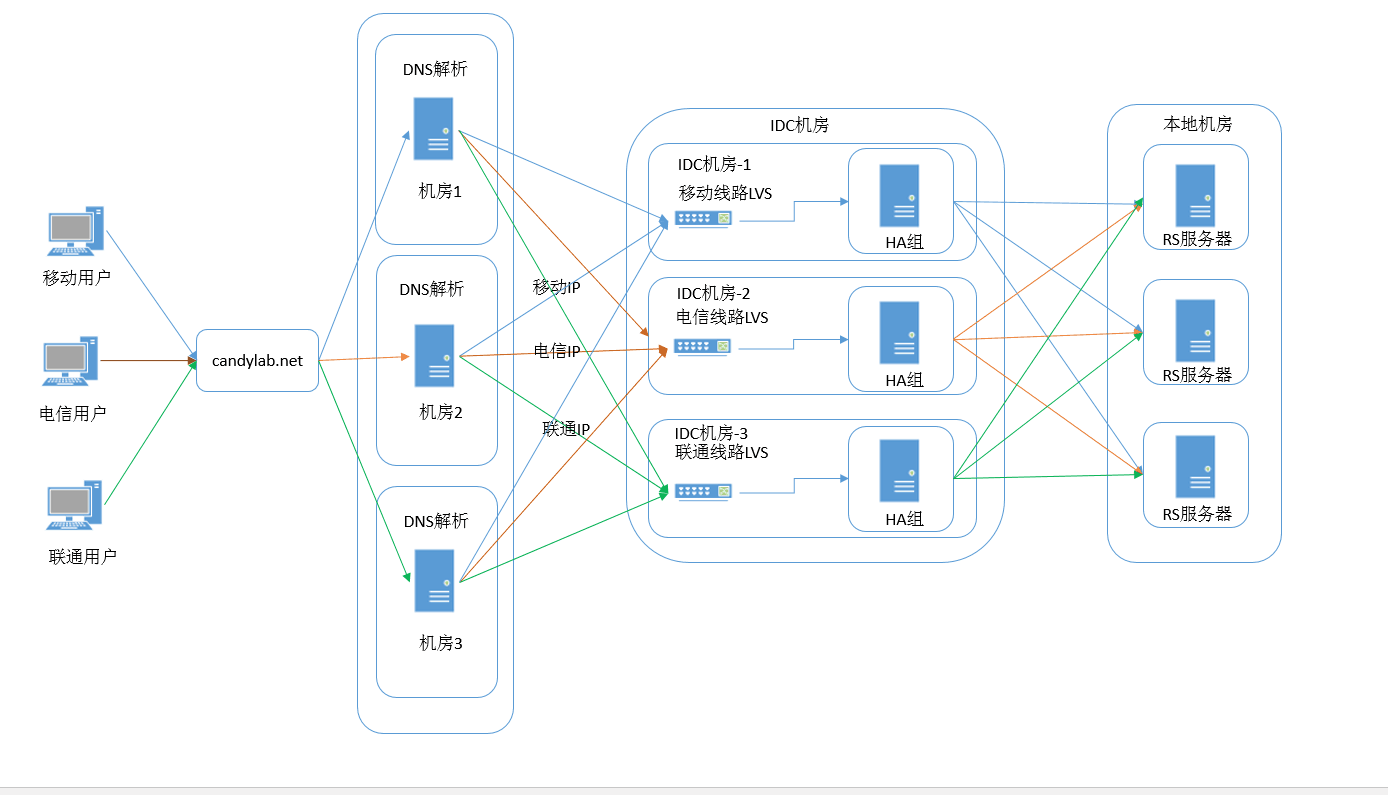
0×03 服务监控点视角
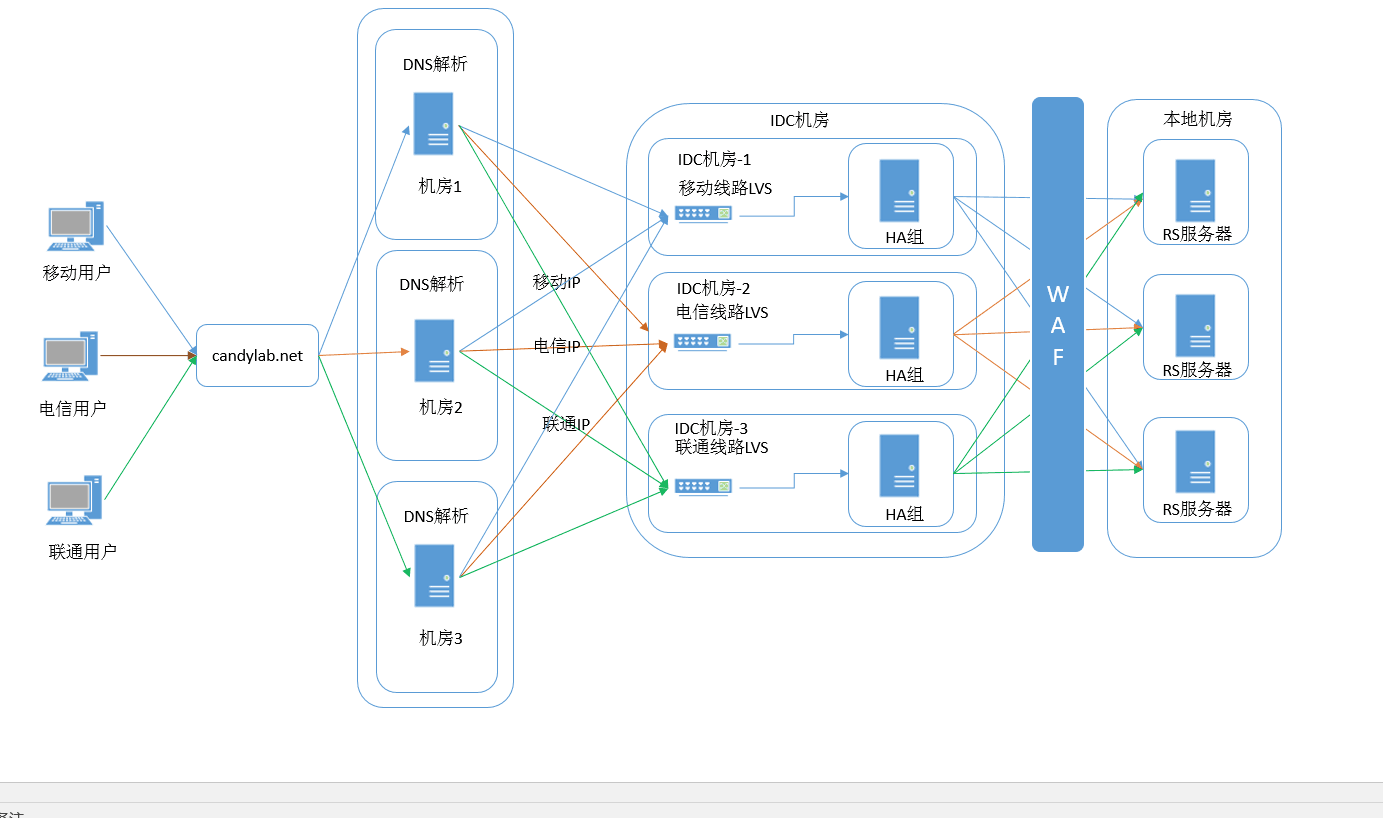
为了保证服务的可用性,部署服务一般都是采用多点多活的方式,针对WEB服务来说, LVS和HA这些类似的负载均衡解决方案就比较常见针对为了保证多线路的用户的使用体验,采用智能DNS也比较常见。用户的请求在到达真实服务器前,到少走一层或是两层以上的服务器,RS轮询服务也需要两到三台服务器。
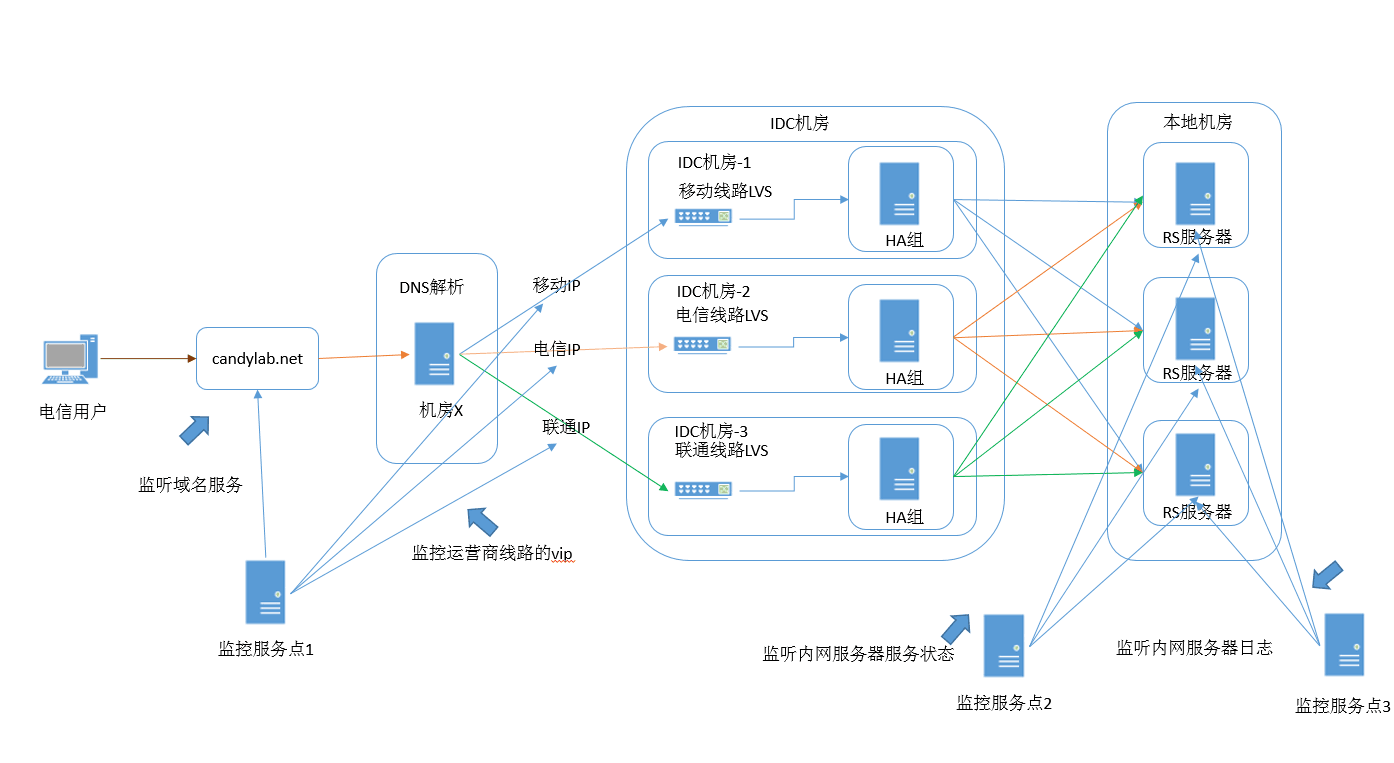
0×04 服务监控点
关系到多个服务器之间的通信,监控的线路比较多,我们简化了一下关系图,只留下一个dns服务器。在这张图上我们至少要关注三个点的监控。
1.域名监控: 我们要直拉通过域名,整体的监控对应服务的可用性。
2.VIP线路监控:通过DNS智能解释,我们根据用户通信服务商对应查IP库,来决定将用户切到那个机房的线路,这些vip也是我们
关注的重点,如果这些vip有问题了,就算在本地机方的服务还活着,用户也访问不了了。
3.本地服务线路状态:上图我们用了3台RS服务器做负载均衡,我们会对三台服务器的线路及服务业务级的可用性进行监控。
4.本地服务器的日志:LVS和HA是针对自身进行备份切换,不针对的RS进行报警和切换,我们通过RS的日志收集来溯源问题和监控服务。
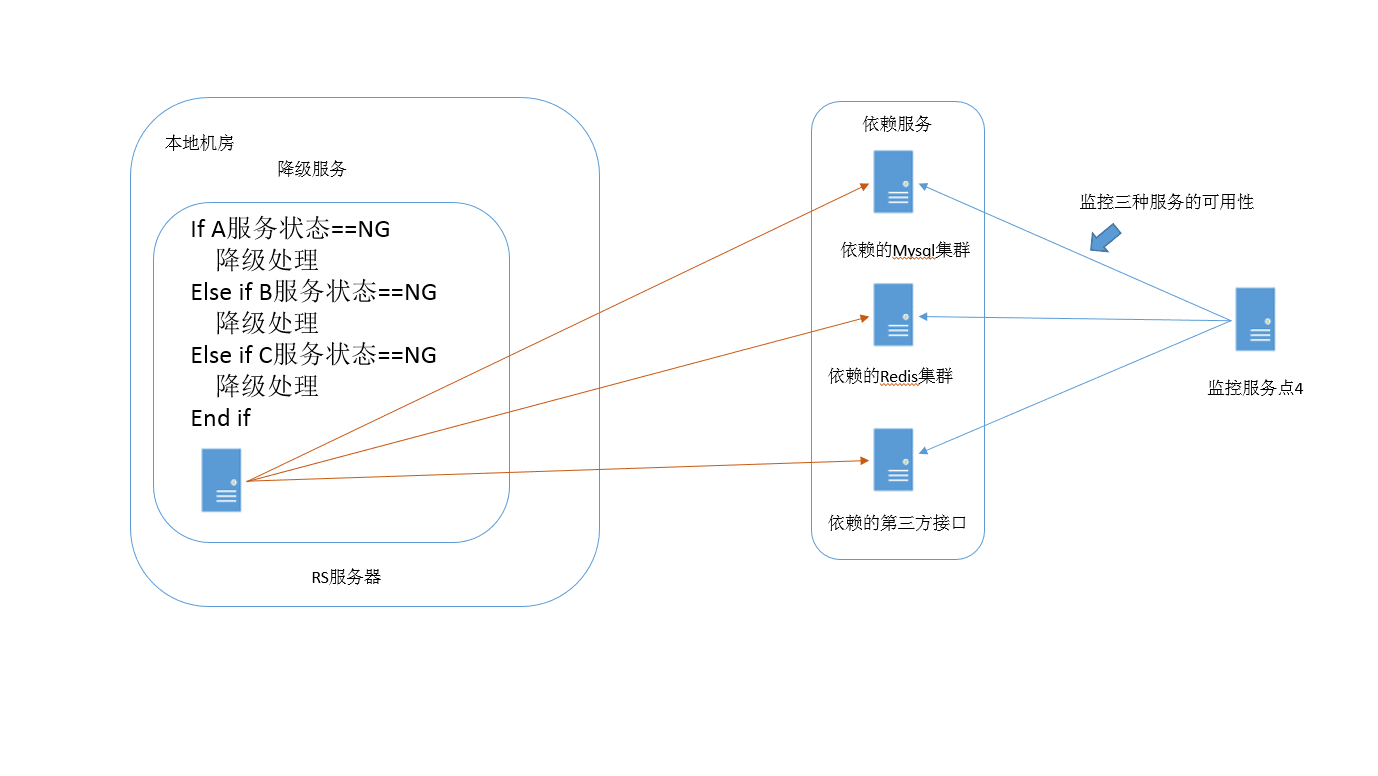
0×05 报警与自动恢复
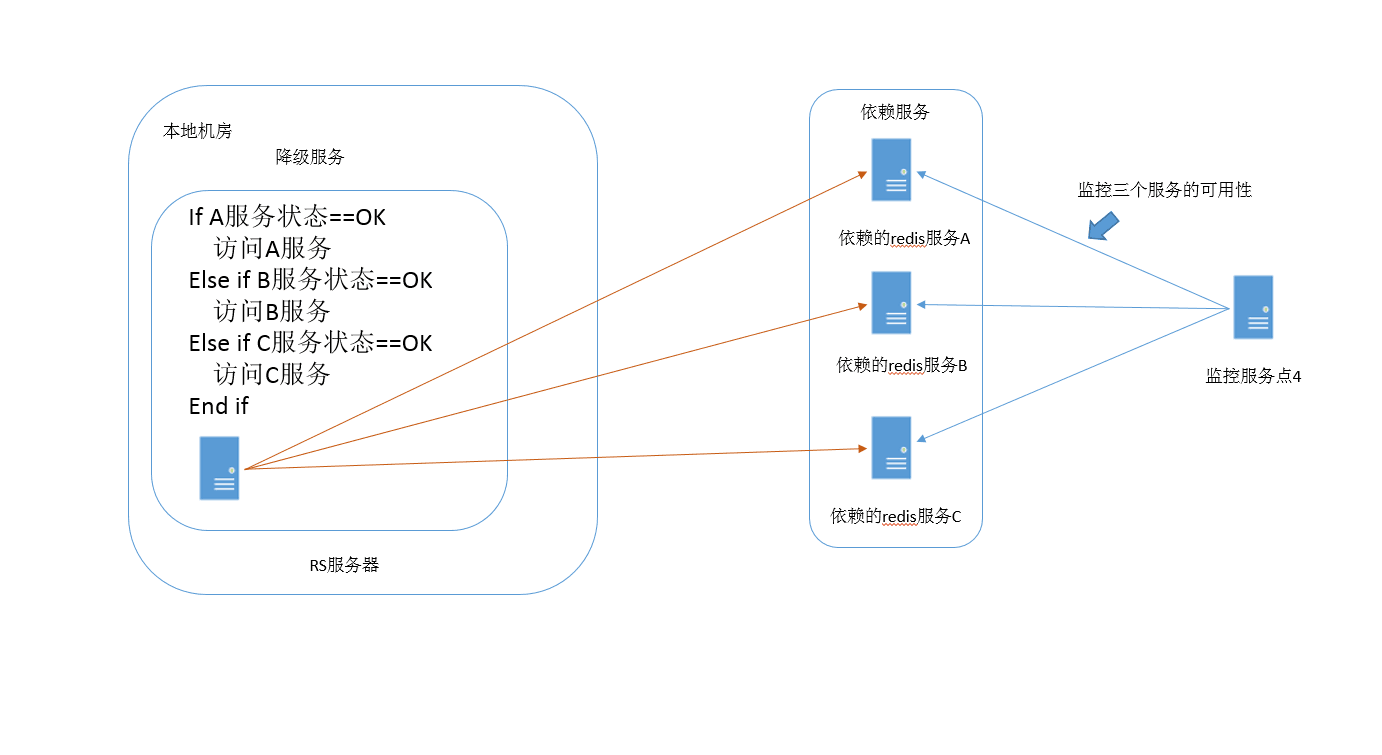
一般复杂一些的服务都不是孤立的,或多或少的会依赖其它服务,一般所依赖的服务发生了问题,服务本身也会发生问题。所以对所有相关的依赖都要做相应的健康,一旦监控出现问题有,就需快速的处理问题。 上面的图就是平时系统中上下链路服务的监控示意。我们平时是监控,但监控出现问题时,我们是改如何处理也是一个问题。 可以在报警后,人员上机房去处理,但工作人员不在现场的时候,或是发现比较晚的情况,这种响应处理就不太理想,所以,可以作一些监控配套自动化的恢复处理。
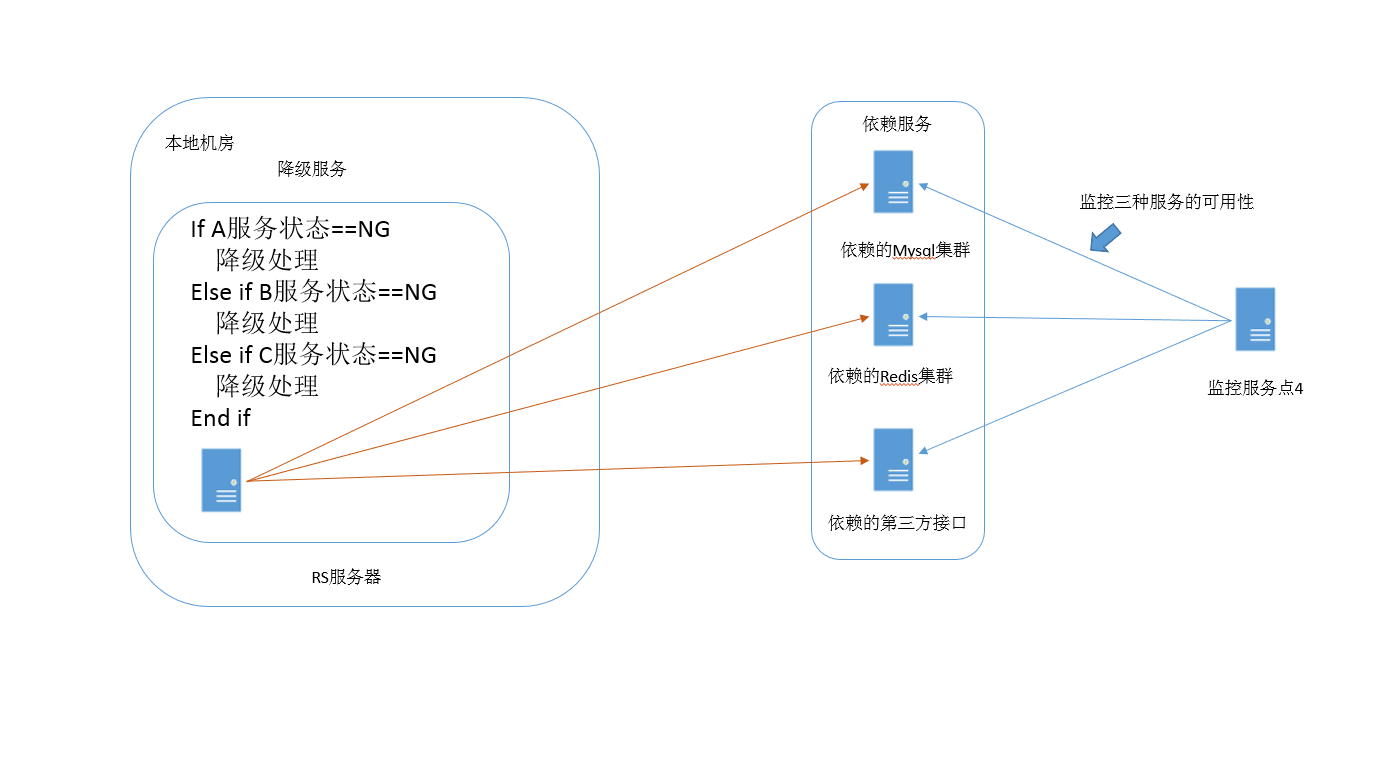
我们用伪指令来描述一下, 依赖服务出现异常情况的处理逻辑,对于常用的依赖服务A、B、C,一旦出现问题,我们可以做一些简单的降级处理。 比如,如果依赖的ES或是数据库出现问题,我们可以把依赖服务切到本地数据库,或是跨过数据库访问,完成plan B方案,继续执行业务,让业务不中断。
0×06 报警与自动切换
0×07 报警与防护
还有一种情况,由于某种原因,我们不能使用集群或是负载多活服务,必须使用本地化服务, 当依赖服务发生故障时,直接切换备用机系统。这种处理的好处也是可以保证系统服务不中断,但切换时要考虑超时延时时间,这样会加长某些操作的用户响应速度。
0×08 报警与防护
作为一个安全系统,我们可以在现有部署结构设计下,加入WAF拦截处理。在负载均衡设备和RS服务器之间,加入WAF功能模块。 如果在这种模式溯源IP需要RS支持TOA,或是在HA上设置溯源IP字段,这样RS的日志看到IP才是真实的IP。如果机房发生DDOS攻击,比如一些异常的UDP垃圾流量或是拥塞请求在LVS断就会发现,而在负载和RS之间的WAF只做WEB防护,而不做DDOS防护。这就是类型网站系统的预警与防护结构。